MemOS算法原理概述
让大模型从一次性对话工具,进化为真正具有长期记忆和自适应能力的智能体。
1. 什么是 MemOS?
当下的大语言模型(LLM)已经展现出强大的生成和推理能力,但它们普遍缺乏真正的「记忆」。
- 在多轮对话中,它们常常遗忘早期信息;
- 在应用场景中,它们无法沉淀用户的个性化偏好;
- 在知识迭代时,它们更新缓慢,无法灵活应对新需求。
这使得 LLM 虽然“聪明”,却难以成为真正的 老师、同事或助手。
MemOS(Memory Operating System) 正是为了解决这一根本性缺陷而提出。
它把「记忆」从一个零散的功能,提升为与算力同等重要的 系统资源,为 LLM 提供:
- 统一的记忆层:跨越单一对话,支撑长期知识沉淀和上下文管理;
- 持久化与结构化能力:让记忆能够被保存、追溯和复用;
- 记忆增强推理:在推理时调用历史经验和偏好,生成更符合用户需求的答案。
相比传统的做法(如单纯依赖参数记忆或临时 KV 缓存),MemOS 的价值在于:
- 它让 AI 不再是“看过就忘”,而是能持续进化和学习;
- 它不仅能回答当下的问题,更能利用过去的积累改善未来的表现;
- 它为开发者提供了统一接口,把“记忆”从复杂的自研逻辑变成标准化能力。
简而言之,MemOS 的目标是:
让大模型从一次性对话工具,进化为真正具有长期记忆和自适应能力的智能体。
2. MemOS架构设计
MemOS 的设计核心,是把「记忆」作为一个独立系统层,和计算、存储一样,成为 AI 应用的基础能力。它的整体架构可以概括为 三层结构: API 与应用接口层、记忆调度与管理层、记忆存储与基础设施层

- 在 API 与应用接口层,MemOS 提供了标准化的 Memory API,开发者可以通过简单的接口实现记忆创建、删除、更新等操作,让大模型具备易于调用和扩展的持久记忆能力,支持多轮对话、长期任务和跨会话个性化等复杂应用场景。
这里的
API 层指的是框架内部的标准化接口设计,用于阐述系统原理与能力边界。不同于云服务对外提供的开发接口 (如add、search等简化封装),后者是基于 MemOS 能力在后端抽象后的统一入口。
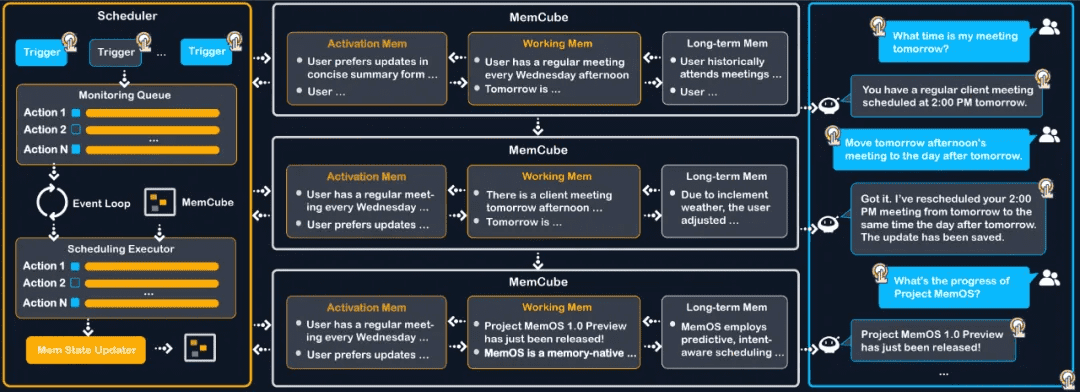
- 在记忆调度与管理层,MemOS 提出了记忆调度(Memory Scheduling)的全新范式,支持基于上下文的 “下一场景预测”(Next-Scene Prediction),可以在模型生成时提前加载潜在需要的记忆片段,显著降低响应延迟、提升推理效率。
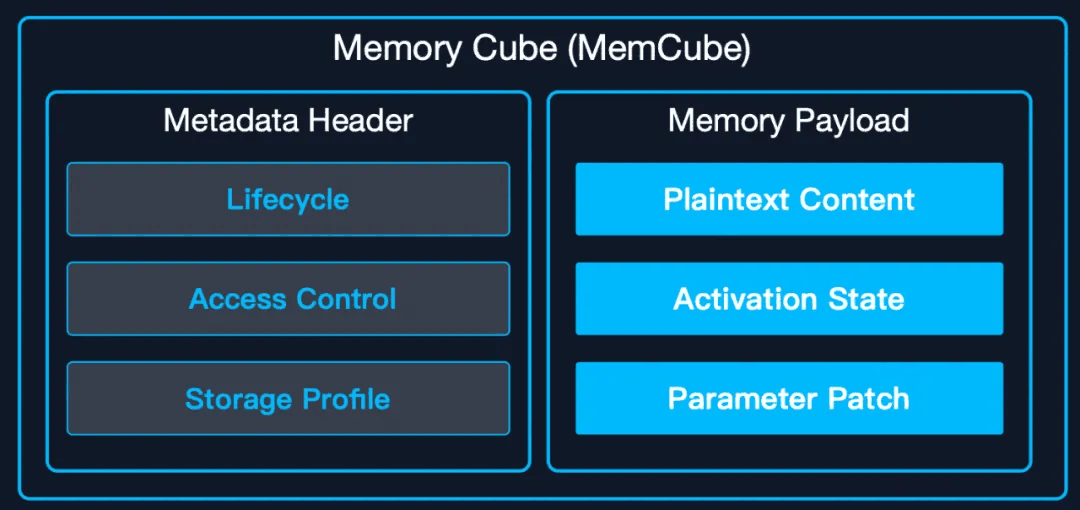
- 而在记忆存储与基础设施层,MemOS 通过标准化的 MemCube 封装,将明文记忆、激活记忆和参数记忆三种形态有机整合。它支持多种持久化存储方式,包括 Graph 数据库、向量数据库等,并具备跨模型的记忆迁移与复用能力。
3. MemOS为什么高效?
从Next-Token Prediction到Next-Scene Prediction
- 在传统的大模型问答系统中,生成流程依然遵循同步的Next-Token机制:模型接收用户问题→实时检索外部片段→按token逐字生成答案。
- 检索或计算产生的任何停顿,都会直接拉长整条推理链路,知识注入与生成紧密耦合,导致GPU容易出现空等,用户端响应时延明显。
- 与这种传统范式不同,MemOS 从记忆建模的视角出发,提出了记忆调度范式,通过设计异步调度框架,提前预测模型可能需要的记忆信息,显著降低实时生成中的效率损耗。
- MemOS 实现了针对MemCube中的三种核心记忆类型(参数记忆、激活记忆、明文记忆),以及外部知识库(包括互联网检索与超大规模本地知识)等多元知识的联合调度。
- 依托对对话轮次与时间差的精准感知,系统能够智能预测下一个场景中可能被调用的记忆内容,并动态路由与预加载所需的明文、参数和激活记忆,从而在生成阶段即刻命中,最大化信息引入的效率和推理的流畅性。

4. MemOS-Preview 版本性能详细评估结果
4.1 LoCoMo记忆评测
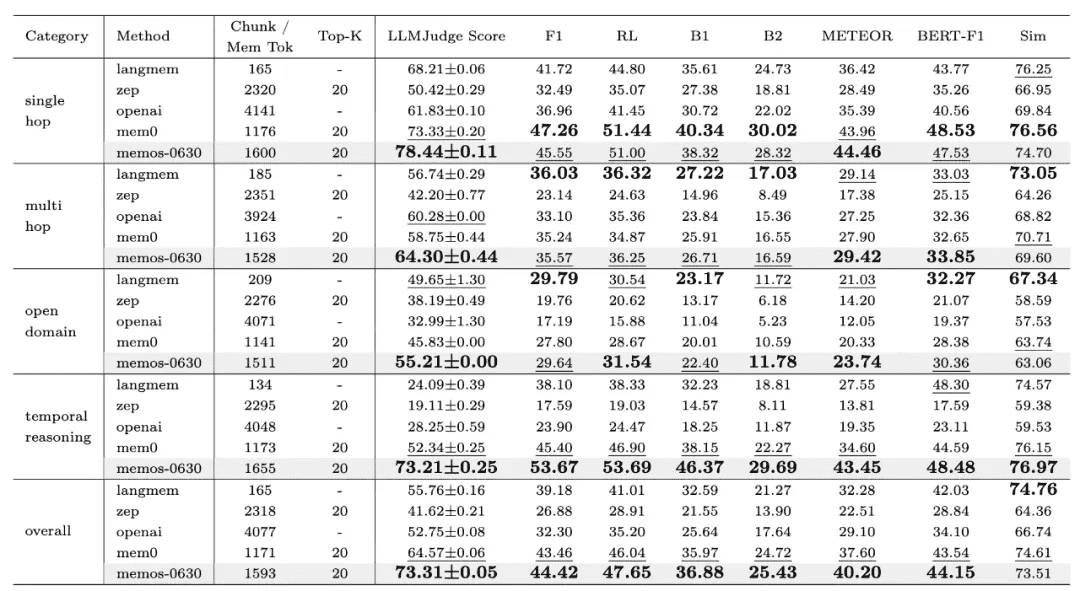
- 为系统性验证MemOS在真实应用场景下的表现,MemOS团队基于LoCoMo数据集进行了全面评测。
- 作为当前业界广泛认可的记忆管理基准,LoCoMo已被多种主流框架采用,用于检验模型的记忆存取能力与多轮对话一致性。
- 从官方公开的评测数据来看,MemOS在准确率和计算效率上均实现了显著提升,相较于OpenAI的全局记忆方案,在关键指标上展现出更优的性能表现,进一步验证了其在记忆调度、管理与推理融合方面的技术领先性。
4.2 KV Cache记忆评测
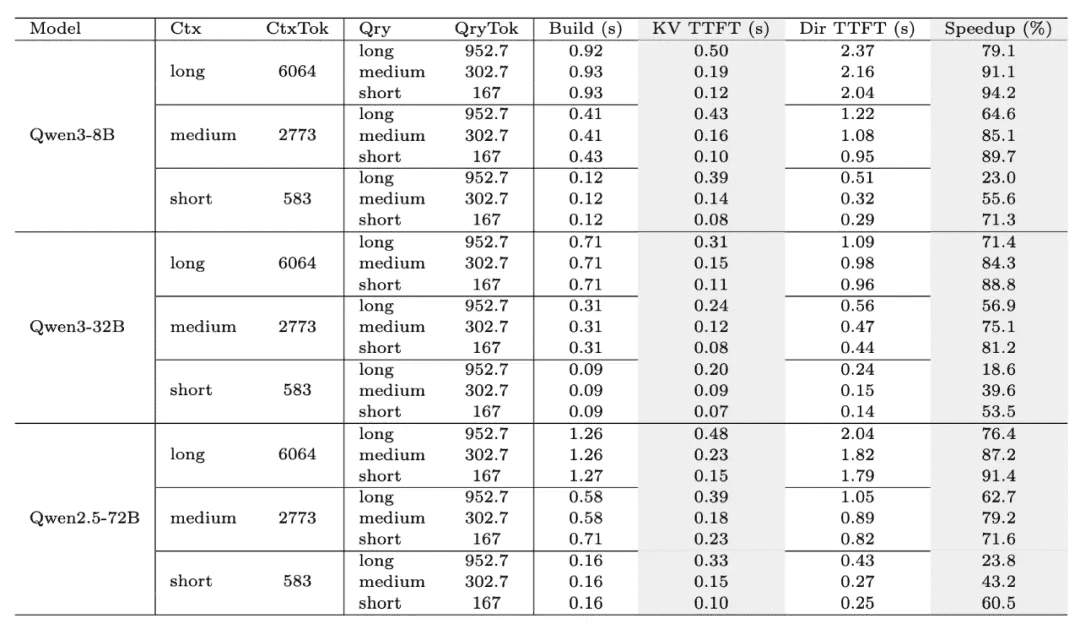
- 除了通用的记忆能力评估,研究团队还重点考察了MemOS所提出的KV Cache记忆机制在推理加速方面的实际效果。
- 通过在不同上下文长度(Short/Medium/Long)以及不同模型规模(8B/32B/72B)下进行对比测试,系统性评估了缓存构建时间(Build)、**首Token响应时间(TTFT)以及整体加速比(Speedup)**等关键指标。
- 实验结果(见图10)表明,MemOS在多种配置下均显著优化了KV Cache的构建与复用效率,使推理过程更加高效流畅,有效缩短了用户的等待时延,并在大规模模型场景中实现了可观的性能加速。
5. 下一步行动
6. 联系我们
