什么是 MemOS?
随着 LLMs 的发展,它们需要处理复杂任务——如多轮对话、长期规划、决策制定和个性化用户体验——赋予它们结构化、管理和演进记忆的能力对于实现真正的长期智能和适应性变得至关重要。
然而,大多数主流 LLMs 仍然严重依赖静态参数化记忆(模型权重)。这使得更新知识、跟踪记忆使用或积累演进的用户偏好变得困难。结果是什么?刷新知识成本高、行为脆弱以及个性化有限。
MemOS 通过将记忆重新定义为具有统一结构、生命周期管理和调度逻辑的核心模块化系统资源来解决这些挑战。它提供了一个基于 Python 的层,位于您的 LLM 和外部知识源之间,实现持久化、结构化和高效的记忆操作。
使用 MemOS,您的 LLM 可以随时间保留知识,更稳健地管理上下文,并使用可解释和可审计的记忆进行推理——解锁更智能、可靠和自适应的 AI 行为。
MemOS 帮助弥合静态参数化权重和动态、用户特定记忆之间的差距。 将其视为您代理的"大脑",具有明文和激活记忆的即插即用模块。
为什么我们需要MemOS?
LLMs 强大,但严重依赖参数化记忆(权重),这些权重难以检查、更新或共享。 典型的向量搜索 (RAG) 有助于检索外部事实,但缺乏统一治理、生命周期控制或跨代理共享。
MemOS 改变了这一点。 将其视为记忆的操作系统: 就像操作系统调度 CPU、RAM 和文件一样,MemOS 调度、转换和治理多种记忆类型——从参数化权重到临时缓存再到明文、可追溯的知识。
MemOS 通过将参数化、激活和明文记忆融合到生命周期中,帮助您的 LLM 演进。
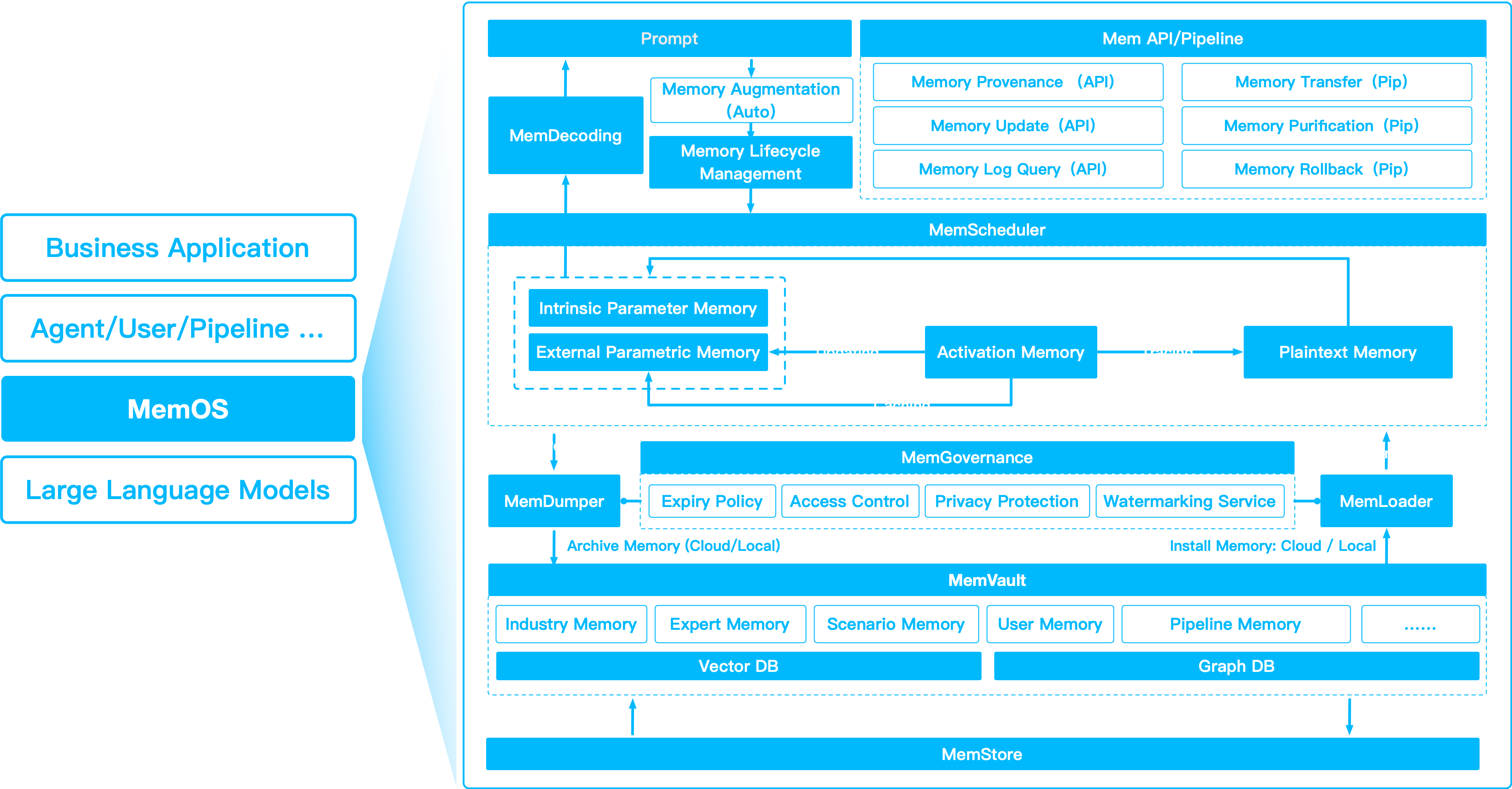
核心构建模块
MemCubes
灵活的容器,容纳一种或多种记忆类型。 每个用户、会话或代理都可以有自己的 MemCube——可交换、可重用和可追溯。
记忆生命周期
每个记忆单元可以流经以下状态:
- 生成 → 激活 → 合并 → 归档 → 冻结
每个步骤都通过来源跟踪和审计日志进行版本控制。旧记忆可以"时间机器"回到之前的版本进行恢复或反事实模拟。
操作与治理
模块包括:
- MemScheduler — 动态转换记忆类型以实现最佳复用。
- MemLifecycle — 管理状态转换、合并和归档。
- MemGovernance — 处理访问控制、编辑、合规性和审计跟踪。
每个记忆单元都携带完整的来源元数据,因此您可以审计谁创建、修改或查询了它。
多视角记忆
MemOS 在生命周期中融合三种记忆形式:
| 类型 | 描述 | 用例 |
|---|---|---|
| 参数记忆 | 知识提炼到模型权重中 | 常青技能、稳定领域事实 |
| 激活记忆 | 用于推理复用的 KV caches 和隐藏状态 | 快速多轮聊天、低延迟生成 |
| 明文记忆 | 文本、文档、图、向量块、用户可见事实 | 语义搜索、演进、可解释记忆 |
随着时间的推移:
- 频繁使用的明文记忆可以提炼为参数化权重。
- 稳定的上下文被提升为 KV cache 以快速注入。
- 使用频率低或过时的知识可以被降级。
MemOS 有什么不同?
- 混合检索 — 符号和语义混合检索、向量和图混合检索。
- 多代理和多用户图 — 私有和共享。
- 来源和审计跟踪 — 每个记忆单元都被治理和可解释。
- 自动 KV cache 提升以重用稳定上下文。
- 记忆的生命周期调度 — 减少陈旧事实或臃肿权重的调用。
适合谁?
- 需要多轮、演进记忆的对话代理
- 处理合规性、领域更新和个性化的企业级 Copilot
- 在共享知识图上协作的多代理系统
- 想要模块化、可查记忆而不是黑盒提示的 AI 构建者
关键要点
MemOS 将您的 LLM 从"只是预测 tokens" 升级为可以记忆、推理和适应的智能演进系统—— 就像您代理思维的操作系统。
使用 MemOS,您的 AI 不仅仅是存储事实——它在成长。
主要特性
- 模块化记忆架构: 支持明文、激活 (KV cache) 和参数化 (adapters/LoRA) 记忆。
- MemCube: 所有记忆类型的统一容器,具有简单的加载/保存和 API 访问。
- MOS: 面向 LLMs 的记忆增强系统,具有即插即用的记忆模块。
- 基于图的后端: 原生支持 Neo4j 和其他图数据库,用于结构化、可解释的记忆。
- 易于集成: 可与 HuggingFace、Ollama 和自定义 LLMs 配合使用。
- 可扩展: 添加您自己的记忆模块或后端。