使用 MemOS 构建智能小说分析系统
🆚 为什么选择MemOS?传统方法 vs MemOS对比
在开始编码之前,让我们看看MemOS到底解决了什么问题:
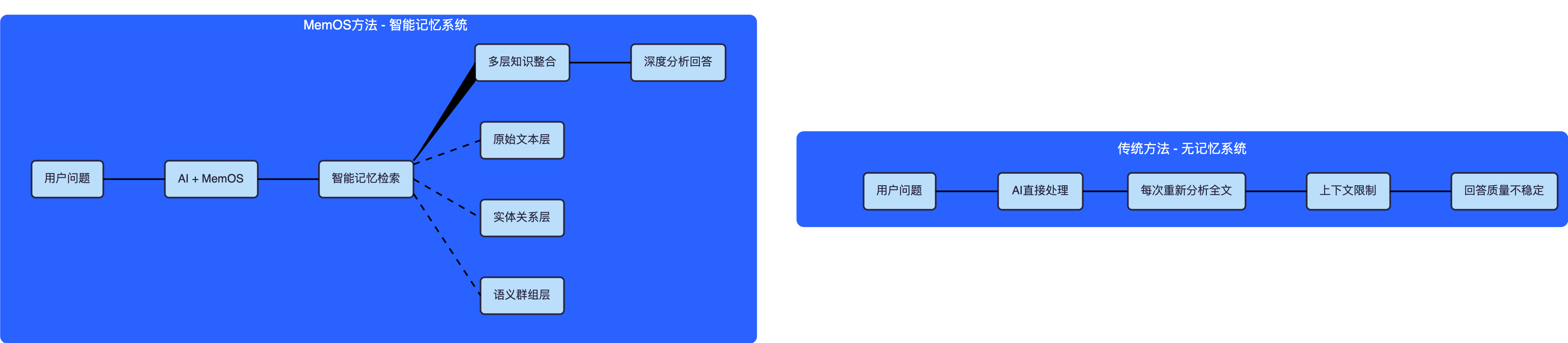
实际效果对比举例:
用户问:"萧峰和段誉的关系如何发展?"
| 传统方法 | MemOS方法 |
|---|---|
| 🐌 重新搜索全文中的相关片段 | ⚡ 直接从关系层检索 |
| 😵 可能遗漏关键情节 | 🎯 完整的关系发展时间线 |
| 📄 只能基于部分文本回答 | 🧠 基于完整人物画像分析 |
💡 为什么使用MemOS内置组件?
想象你要做一道菜,你可以选择:
- 🔧 自己制作所有调料 - 费时费力,质量难保证
- 🏪 使用专业调料品牌 - 省时高效,品质稳定
MemOS就像是专业的"调料品牌",它已经为我们准备好了:
- 🤖 智能对话客户端 - 自动处理网络问题、支持多种AI模型
- 🧠 向量化服务 - 专门优化的中文文本理解能力
- ⚙️ 配置管理 - 简单易用的参数设置
学习收获: 通过本章,你将学会如何像专业开发者一样,优先使用成熟的组件库,而不是从零开始编写复杂的底层代码。
章节引言
本章将带你构建一个基于《天龙八部》小说的智能记忆分析系统,实现从原始文本到结构化记忆的完整转换流程。
核心技术架构:
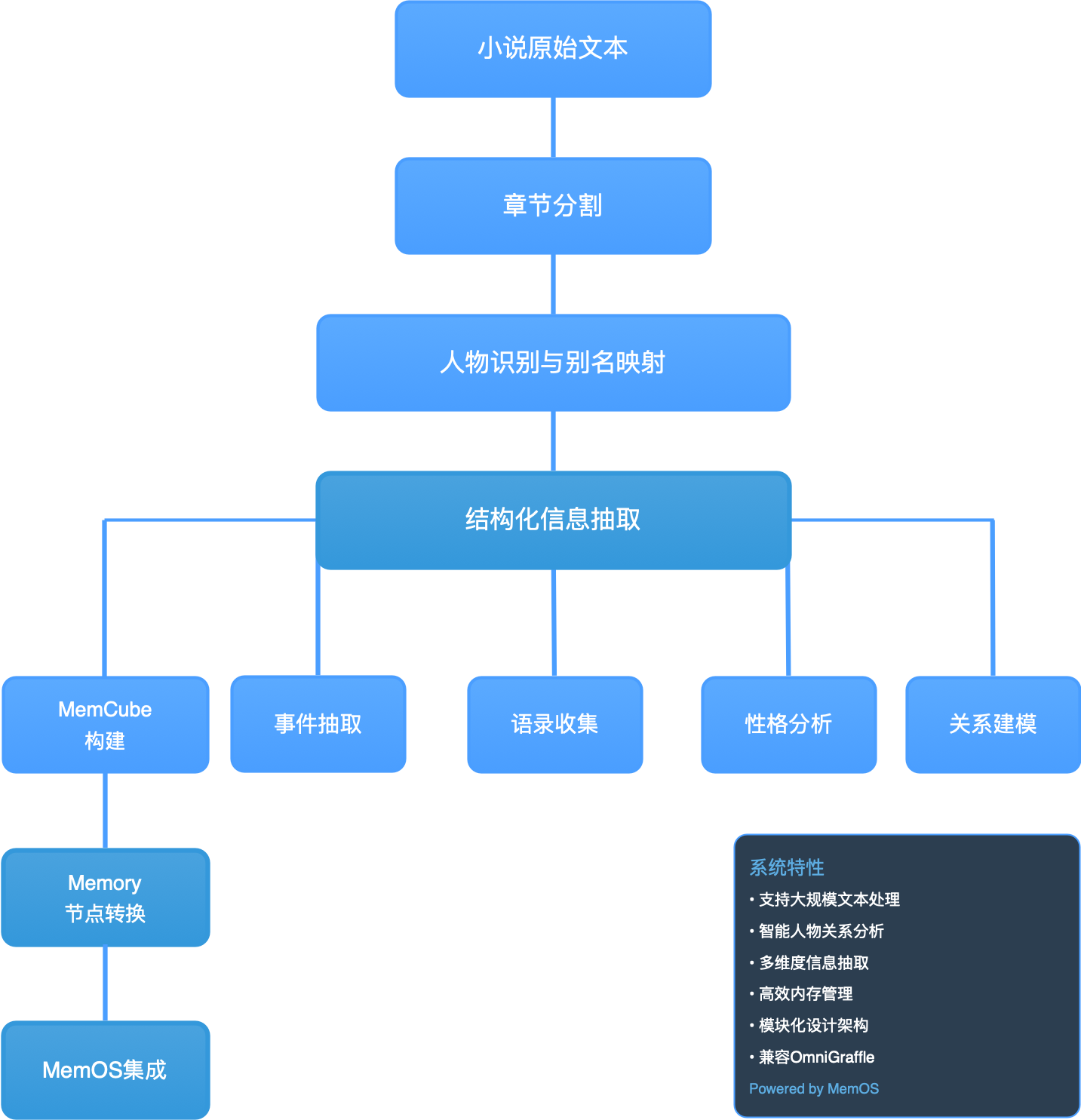
数据处理流水线:
- 文本预处理 → 章节切分 → 结构化输入
- AI驱动抽取 → 人物建模 → MemCube生成
- 格式转换 → 图结构构建 → MemOS记忆库
系统设计理念:
- 本章提供了从非结构化文本到智能记忆系统的完整解决方案
- 每个配方都解决数据流水线中的关键技术问题
- 支持大规模文本的并行处理和增量更新
- 构建可查询、可推理的智能记忆网络
环境配置
import requests
import json
import os
import pickle
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import re
from typing import Dict, List, Optional, Any, Set, Tuple
from dataclasses import dataclass, field
from enum import Enum
配方3.0:文本预处理与API环境配置
🎯 目标
建立小说文本的结构化处理基础,包括章节分割和AI服务连接。
📖 章节分割算法
通过正则表达式识别章节标题,将长篇小说切分为可处理的片段:
def extract_all_chapters(text: str, output_dir: str = "chapters"):
# 匹配所有"第X章"标题的位置
pattern = r"(第[一二三四五六七八九十百千零〇两\d]+章)"
matches = list(re.finditer(pattern, text))
if not matches:
raise ValueError("未找到任何章节标题")
os.makedirs(output_dir, exist_ok=True)
for i in range(len(matches)):
start_idx = matches[i].start()
end_idx = matches[i+1].start() if i+1 < len(matches) else len(text)
chapter_title = matches[i].group()
chapter_number = i + 1 # 用自然数编号
chapter_text = text[start_idx:end_idx].strip()
filename = os.path.join(output_dir, f"chapter{chapter_number}.txt")
with open(filename, "w", encoding="utf-8") as f:
f.write(chapter_text)
print(f"✅ 已保存:{filename}({chapter_title})")
# 读取整本小说
with open("天龙八部.txt", "r", encoding="utf-8") as f:
full_text = f.read()
# 提取并保存所有章节
extract_all_chapters(full_text)
🔧 API客户端配置
建立稳定的AI服务连接,支持不同任务类型的模型调用:
# JSON修复功能配置
try:
from json_repair import repair_json
HAS_JSONREPAIR = True
print("✓ jsonrepair库已加载,JSON修复功能已启用")
except ImportError:
HAS_JSONREPAIR = False
print("⚠ jsonrepair库未安装,将使用基础修复策略")
def repair_json(text):
return text
class TaskType(Enum):
EVENT_EXTRACTION = "event_extraction"
class MemOSLLMClient:
"""对话客户端 - 使用MemOS让AI调用变得简单可靠"""
def __init__(self, api_key: str, api_base: str = "https://api.openai.com/v1", model: str = "gpt-4o"):
# 🔧 第一步:导入MemOS的智能组件
from memos.llms.factory import LLMFactory
from memos.configs.llm import LLMConfigFactory
# 🎯 第二步:告诉MemOS我们要用什么AI模型
llm_config_factory = LLMConfigFactory(
backend="openai", # 使用OpenAI(也支持其他厂商)
config={
"model_name_or_path": model, # 你选择的AI模型
"api_key": api_key, # 你的API密钥
"api_base": api_base, # API服务地址
"temperature": 0.8, # 创造性程度
"max_tokens": 8192, # 最大回复长度
"top_p": 0.9, # 回复质量控制
}
)
# 🚀 第三步:让MemOS帮我们创建一个对话客户端
# MemOS会自动处理网络重试、连接池等复杂问题
self.llm = LLMFactory.from_config(llm_config_factory)
print(f"✅ 对话客户端已就绪!使用模型: {model}")
def call_api(self, messages: List[Dict], task_type: TaskType, timeout: int = 1800) -> Dict:
"""和AI对话的方法 - 就这么简单!"""
try:
response = self.llm.generate(messages)
return {
"status": "success", # 成功了!
"content": response, # AI的回答
"model_used": self.llm.config.model_name_or_path # 用的哪个模型
}
except Exception as e:
# 😅 如果出错了,MemOS会告诉我们具体什么问题
return {
"status": "error",
"error": str(e),
"model_used": self.llm.config.model_name_or_path
}
🚀 批量处理初始化
建立章节遍历机制,为后续并行处理做准备:
# 🎯 配置你的AI助手(使用MemOS让一切变简单)
API_KEY = "YOUR_API_KEY" # 🔑 填入你的OpenAI API密钥
API_BASE = "https://api.openai.com/v1" # 🌐 API服务地址(通常不用改)
MODEL_NAME = "gpt-4o" # 🤖 选择你喜欢的AI模型
# 🚀 创建你的专属AI助手
api_client = MemOSLLMClient(
api_key=API_KEY,
api_base=API_BASE,
model=MODEL_NAME
)
# 现在你就有了一个聪明、稳定、易用的AI助手!
memcubes = {} # 全局人物记忆库
alias_to_name = {} # 别名到标准名映射
chapter_folder = "chapters"
# 按章节顺序处理
chapter_files = sorted(
[os.path.join(chapter_folder, f) for f in os.listdir(chapter_folder)
if f.startswith("chapter") and f.endswith(".txt")],
key=lambda x: int(re.search(r'chapter(\d+)', x).group(1))
)
for chapter_file in chapter_files:
chapter_id = chapter_file.replace(".txt", "")
print(f"\n📖 正在处理:{chapter_id}")
with open(chapter_file, "r", encoding="utf-8") as f:
content = f.read()
# 后续处理逻辑...
配方3.1:AI驱动的人物识别与别名统一
🎯 目标
使用AI自动识别小说中的人物,建立别名映射关系,初始化人物记忆容器。
🧠 智能人物识别
通过精心设计的prompt实现准确的人物抽取和别名归并:
@staticmethod
def extract_character_names_prompt(paragraph: str, alias_to_name: dict = None):
system_msg = (
"你是一个小说人物识别专家,请从以下小说片段中提取所有明确提及的人物。\n"
"对于每个人物,请标注该人物的标准姓名(如"乔峰")以及其在该片段中出现的所有称呼、别名、代称(如"丐帮帮主"、"乔帮主"、"那大汉")。\n\n"
"请以如下格式返回 JSON:\n"
"[\n"
" {\n"
" \"name\": \"乔峰\",\n"
" \"aliases\": [\"丐帮帮主\", \"乔帮主\", \"那大汉\"]\n"
" }\n"
"]\n\n"
"⚠️ 注意:\n"
"1. 只包含人物,不包括地点或组织。\n"
"2. 同一人物的多个称呼应统一归并在同一个条目中。\n"
"3. 所有字段使用标准 JSON 格式。不要包含 markdown 符号或注释。\n"
"4. 如果无法确定某个称呼是否为新人物,可以暂时保留为独立项。"
)
if alias_to_name:
system_msg += "\n\n以下是已知别名对应的标准人物姓名,请尽量将新识别到的称呼归入已有人物中:\n"
alias_map_str = json.dumps(alias_to_name, ensure_ascii=False, indent=2)
system_msg += alias_map_str
return [
{"role": "system", "content": system_msg},
{"role": "user", "content": f"小说片段如下:\n{paragraph}"}
]
💾 MemCube初始化与别名管理
为每个识别出的人物创建结构化记忆容器:
def init_memcube(character_name: str, chunk_id: str):
"""初始化人物记忆立方体 - 包含所有核心字段"""
return {
"name": character_name,
"first_appearance": chunk_id,
"aliases": [character_name],
"events": [],
"utterances": [],
"speech_style": "",
"personality_traits": [],
"emotion_state": "",
"relations": []
}
# 执行人物识别和初始化
name_prompt = Prompt.extract_character_names_prompt(content, alias_to_name)
name_result = api_client.call_api(name_prompt, TaskType.EVENT_EXTRACTION, timeout=1800)
try:
extracted = json.loads(name_result.get("content", "").strip("```json").strip("```").strip())
except:
extracted = []
# 更新人物库和别名映射
for item in extracted:
std_name = item["name"]
aliases = item.get("aliases", [])
# 初始化或更新 MemCube
if std_name not in memcubes:
print(f"🆕 新人物识别:{std_name}")
memcubes[std_name] = init_memcube(std_name, chapter_id)
memcubes[std_name]["aliases"] = []
# 合并别名列表
all_aliases = list(set(memcubes[std_name].get("aliases", []) + aliases))
memcubes[std_name]["aliases"] = all_aliases
# 构建全局别名映射
for alias in [std_name] + aliases:
alias_to_name[alias] = std_name
配方3.2:结构化记忆内容抽取
🎯 目标
使用AI从小说文本中抽取结构化的人物信息,包括事件、语录、性格、情绪和关系网络。
🎭 多维度信息抽取Prompt
设计精确的prompt模板,确保AI返回标准化的JSON数据:
@staticmethod
def update_character_prompt(character_name: str, unfinished_events: list, paragraph: str):
return [
{
"role": "system",
"content": (
"你是小说人物建模专家,将分析某人物的未完成事件与最新小说片段。\n"
"你的任务是更新以下字段:\n"
"- events:事件列表(更新状态、添加新事件,包含子字段 event_id、action、motivation、impact、involved_entities、time、location、event、if_completed)\n"
"- 每个事件必须包含唯一的 \"event_id\",例如 \"event_001\"、\"event_002\" 等。\n"
"- utterances:说过的话(含时间或事件编号)\n"
"- speech_style:说话风格(如 古典、直接、讽刺等)\n"
"- personality_traits:性格(如 冷静、冲动)\n"
"- emotion_state:当前情绪状态\n"
"- relations:与他人的关系列表\n\n"
"请特别注意以下要求:\n"
"1. 请认真判断现有未完成事件是否已经在新片段中结束。\n"
"2. 如果某事件已有结局或结果,请务必将其 `if_completed` 字段标记为 true。\n"
"3. 如果小说片段中出现与该人物相关的新事件,请添加新的事件条目。\n"
"最终请输出以下 JSON 结构:\n"
"{\n"
" \"events\": [...],\n"
" \"utterances\": [...],\n"
" \"speech_style\": \"...\",\n"
" \"personality_traits\": [...],\n"
" \"emotion_state\": \"...\",\n"
" \"relations\": [...]\n"
"}\n\n"
"⚠️ 请注意:\n"
"1. 所有字段名必须使用双引号包裹(JSON 标准格式)。\n"
"2. 不要添加注释符号、额外说明或 markdown 符号。\n"
"3. 仅返回完整 JSON 对象,不能是数组或其他格式。\n"
"4. 如没有内容可填,请使用空数组 [] 或空字符串 \"\"。\n"
)
},
{
"role": "user",
"content": (
f"人物姓名:{character_name}\n"
f"当前未完结事件如下(JSON):\n{json.dumps(unfinished_events, ensure_ascii=False, indent=2)}\n\n"
f"小说片段如下:\n{paragraph}\n\n"
"请按上述格式返回该人物的更新信息。"
)
}
]
🔄 智能数据合并算法
实现事件状态追踪和增量更新机制:
def get_unfinished_events(memcube: dict):
"""获取未完成的事件列表 - 用于上下文连续性"""
return [event for event in memcube.get("events", []) if not event.get("if_completed", False)]
def merge_events(old_events: list, new_events: list):
"""智能事件合并 - 处理状态更新和新增事件"""
event_dict = {e["event_id"]: e for e in old_events}
for new_event in new_events:
eid = new_event["event_id"]
if eid in event_dict:
# 合并策略:新字段优先,保留历史信息
merged = event_dict[eid].copy()
for key, value in new_event.items():
if value not in [None, "", []]:
merged[key] = value
event_dict[eid] = merged
else:
event_dict[eid] = new_event # 新事件直接加入
return list(event_dict.values())
def merge_unique_list(old: list, new: list):
"""列表去重合并 - 保持原有顺序"""
combined = old + new
seen = set()
result = []
for item in combined:
if isinstance(item, dict):
key = json.dumps(item, sort_keys=True, ensure_ascii=False)
else:
key = str(item)
if key not in seen:
seen.add(key)
result.append(item)
return result
⚡ 并行处理引擎
使用线程池实现高效的批量人物更新:
# 并行更新所有人物状态
with ThreadPoolExecutor(max_workers=8) as executor:
futures = {
executor.submit(update_memcube_for_character, name, memcube, content, chapter_id): name
for name, memcube in memcubes.items()
}
for future in as_completed(futures):
name = futures[future]
try:
name, updated, error = future.result()
if error or not updated:
print(f"⚠️ 更新失败:{name} in {chapter_id} -> {error}")
continue
# 智能合并更新结果
memcube = memcubes[name]
memcube["events"] = merge_events(memcube["events"], updated.get("events", []))
memcube["utterances"].extend(updated.get("utterances", []))
if updated.get("speech_style"):
memcube["speech_style"] = updated["speech_style"]
memcube["personality_traits"] = merge_unique_list(
memcube["personality_traits"], updated.get("personality_traits", [])
)
if updated.get("emotion_state"):
memcube["emotion_state"] = updated["emotion_state"]
memcube["relations"].extend(updated.get("relations", []))
except Exception as e:
print(f"⚠️ 并行执行异常:{name} -> {e}")
配方3.3:基于记忆的智能推理系统
🎯 目标
基于构建的MemCube实现小说情节推理、合理性评估、情绪分析等高级功能。
🔮 情节推演引擎
利用人物的完整记忆信息进行故事发展预测:
@staticmethod
def speculate_event_outcome(character_name: str, memcube: dict, user_input: str):
"""基于人物记忆的情节推演 - 生成小说风格的叙述"""
return [
{
"role": "system",
"content": (
"你是一位小说剧本推演专家。\n"
"你将获得所有人物的完整 JSON 信息(包括事件链、性格、情绪、关系等)以及一条用户提出的假设性情节。\n"
"你的任务是基于这些人物的背景、未完成事件、关系网、性格与动机,合理地推演故事可能的发展。\n"
"请生成完整的小说段落风格的叙述(不是列表、不是 JSON),描写故事如何展开。\n"
"注意语言风格应与原小说保持一致(如古典武侠风)。"
)
},
{
"role": "user",
"content": (
f"人物姓名:{character_name}\n\n"
f"人物信息如下(JSON 格式):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"用户的假设性情节如下:\n{user_input}\n\n"
"请基于上述信息推演故事的发展,返回小说式语言的叙述,不要包含任何解释性语言或 JSON。"
)
}
]
@staticmethod
def evaluate_plot_reasonableness(character_name: str, memcube: dict, user_input: str):
"""剧情合理性分析 - 基于人物逻辑判断情节可信度"""
return [
{
"role": "system",
"content": (
"你是一个小说人物行为合理性分析专家。\n"
"你将获得所有人物的完整 JSON 信息(包括事件链、性格、情绪、关系等)以及用户提出的一条假设性剧情。\n"
"你的任务是:\n"
"1. 判断该剧情是否符合该人物的行为逻辑、性格特征、情绪状态以及当前背景。\n"
"2. 如不合理,请指出具体不合理的地方,并说明原因。\n"
"3. 如合理,请说明其合理性,并简要描述该剧情如何顺理成章地发生。\n\n"
"返回格式:\n"
"- 合理性评估:合理 / 不合理 / 有条件合理\n"
"- 分析说明:详细解释是否符合人物动机、关系与背景\n"
"- 建议:如有必要,提出修改建议或更合理的替代表达\n\n"
"请用简洁中文回答,不要生成小说正文或 JSON 结构。"
)
},
{
"role": "user",
"content": (
f"人物姓名:{character_name}\n\n"
f"所有人物的完整信息如下(JSON 格式):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"用户提出的剧情设想如下:\n{user_input}\n\n"
"请你判断这个剧情是否符合该人物当前的状态与逻辑,并说明理由。"
)
}
]
🎭 多维度分析框架
提供情绪轨迹、冲突进展、立场判断等专业分析工具:
@staticmethod
def emotion_trajectory_prompt(character_name: str, memcube: dict, user_input: str):
"""情绪轨迹分析 - 预测人物情绪变化"""
return [
{
"role": "system",
"content": (
"你是一个小说人物情绪轨迹分析专家。\n"
"你将获得某个人物的完整信息(包括事件、性格、情绪、关系等)和用户设想的一段剧情。\n"
"请判断在该剧情中,该人物的情绪是否会发生变化。\n\n"
"你的任务是:\n"
"1. 判断该剧情设想中是否包含情绪变化。\n"
"2. 如果有,请指出情绪类型,并解释该变化是如何被激发的。\n"
"3. 如果没有,请说明为何情绪保持稳定。\n\n"
"返回格式:\n"
"- 情绪变化:有 / 无\n"
"- 当前情绪:xxx\n"
"- 变化原因:xxx\n"
"请使用简洁中文作答。"
)
},
{
"role": "user",
"content": (
f"人物姓名:{character_name}\n\n"
f"该人物的完整信息如下(JSON):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"用户设想剧情如下:\n{user_input}"
)
}
]
@staticmethod
def conflict_progression_prompt(character_name: str, memcube: dict, user_input: str):
"""冲突演化分析 - 追踪人物间矛盾发展"""
return [
{
"role": "system",
"content": (
"你是一个小说人物之间矛盾关系演化的分析专家。\n"
"你将获得某人物的完整资料(JSON 格式)以及用户提出的一条设想剧情。\n"
"请判断在这条剧情中,是否涉及与他人之间的矛盾进展。\n\n"
"你的任务是:\n"
"1. 判断该设想剧情中是否涉及已有或潜在冲突对象。\n"
"2. 如果有,请判断该关系是否发生变化(如激化、缓和或解决)。\n"
"3. 简述冲突变化的原因。\n\n"
"返回格式:\n"
"- 对手:xxx\n"
"- 当前阶段:xxx(如:潜在 → 升级 → 缓和 → 解决)\n"
"- 变化原因:xxx\n"
"请使用简洁中文作答。"
)
},
{
"role": "user",
"content": (
f"人物姓名:{character_name}\n\n"
f"该人物的完整信息如下(JSON):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"用户设想剧情如下:\n{user_input}"
)
}
]
💡 实际应用示例
# 加载已构建的人物记忆库
with open("memcubes1.json", "r", encoding="utf-8") as f:
memcubes = json.load(f)
character_name = "段誉"
user_input = "如果段誉没有出现在剑湖宫比武大会,事情会怎样?"
# 执行情节推演
prompt = Prompt.speculate_event_outcome(character_name, memcubes[character_name], user_input)
response = api_client.call_api(prompt, TaskType.EVENT_EXTRACTION)
print(response.get("content", "❌ 没有返回"))
配方3.4:Embedding模型优化配置
🔄 中文文本检索的Embedding模型切换
切换原因说明:
原始代码使用nomic-embed模型进行文本向量化,但该模型主要针对英文文本优化,在处理中文小说内容时存在以下问题:
- 中文语义理解能力有限:nomic-embed-text模型主要基于英文语料训练,对中文语言的语义理解和文本关系捕获能力较弱
- 检索精度不足:在《天龙八部》等中文小说的人物、事件、关系检索中,语义相似度计算不够准确
- 文化背景缺失:无法很好地理解中文文学作品中的武侠、历史、文化等特定语境
推荐替换方案:
根据Mem0官方文档和中文embedding模型评测,推荐以下配置:
方案一:OpenAI Embedding(推荐)
config = {
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-large", # 支持多语言,中文效果优秀
"embedding_dims": 3072,
"api_key": "YOUR_OPENAI_API_KEY"
}
}
}
优势:
- 支持中英双语,在中文文本检索任务上表现优异
- 向量维度更高(3072),语义表示更丰富
- 在MTEB-zh评测中表现良好
方案二:M3E模型(开源替代)
config = {
"embedder": {
"provider": "huggingface",
"config": {
"model": "moka-ai/m3e-base", # 专为中文优化的开源模型
"embedding_dims": 768
}
}
}
优势:
- 专门针对中文训练,在中文文本分类和检索上优于OpenAI ada-002
- 支持异质文本检索,适合小说人物关系和事件检索
- 完全开源,无API调用费用
方案三:本地部署
config = {
"embedder": {
"provider": "ollama",
"config": {
"model": "moka-ai/m3e-base",
"ollama_base_url": "http://localhost:11434"
}
}
}
性能对比数据:
根据MTEB-zh评测结果:
| 模型 | 中文文本分类准确率 | 中文检索 ndcg@10 | 优势 |
|---|---|---|---|
| nomic-embed | 未测试 | 未测试 | 英文优化 |
| OpenAI text-embedding-3-large | 0.6231 | 0.7786+ | 多语言支持 |
| M3E-base | 0.6157 | 0.8004 | 中文专优 |
配方3.5:Memory图结构转换器
🎯 目标
将MemCube数据转换为MemOS兼容的Memory节点格式,构建可查询的知识图谱。
🏗️ Memory节点生成
将人物事件和关系转换为标准化的Memory对象:
def create_memory_node(content: str, entities: list, key: str, memory_type: str = "fact") -> dict:
"""创建标准化的Memory节点"""
node_id = str(uuid.uuid4())
now = datetime.now().isoformat()
# 模拟embedding(实际应用中应使用真实的embedding服务)
embedding = [0.1] * 768 # 示例维度
return {
"id": node_id,
"memory": content,
"metadata": {
"user_id": "",
"session_id": "",
"status": "activated",
"type": "fact",
"confidence": 0.99,
"entities": entities,
"tags": ["事件"] if "事件" in key else ["关系"],
"updated_at": now,
"memory_type": memory_type,
"key": key,
"sources": [],
"embedding": embedding,
"created_at": now,
"usage": [],
"background": ""
}
}
🔄 批量转换处理
实现高效的MemCube到Memory的转换流水线:
INPUT_FILE = "memcube_all.json"
OUTPUT_FILE = "memory_graph.json"
with open(INPUT_FILE, "r", encoding="utf-8") as f:
memcube_data = json.load(f)
nodes = []
edges = []
for character, data in memcube_data.items():
previous_event_id = None
# === 事件序列转换 ===
for event in data.get("events", []):
memory_text = f"{character}在{event.get('time')}于{event.get('location')},因为{event.get('motivation')},进行了{event.get('action')},结果是{event.get('impact')}。"
entities = [character] + event.get("involved_entities", [])
node = create_memory_node(
content=memory_text,
entities=entities,
key=f"{character}的事件:{event.get('action')}"
)
nodes.append(node)
# 建立事件时序关系
if previous_event_id:
edges.append({
"source": previous_event_id,
"target": node["id"],
"type": "FOLLOWS"
})
previous_event_id = node["id"]
# === 关系网络聚合 ===
relations_texts = []
seen = set()
for relation in data.get("relations", []):
name = relation.get("name") or relation.get("人物") or relation.get("character")
relation_text = relation.get("relation") or relation.get("relationship") or relation.get("关系")
if not name or not relation_text:
continue
dedup_key = (str(name), str(relation_text))
if dedup_key in seen:
continue
seen.add(dedup_key)
relations_texts.append(f"与{name}是{relation_text}")
if relations_texts:
memory_text = f"{character}" + ",".join(relations_texts) + "。"
entities = [character]
node = create_memory_node(
content=memory_text,
entities=entities,
key=f"{character}的关系汇总",
)
nodes.append(node)
# 保存转换结果
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
json.dump({
"nodes": nodes,
"edges": edges
}, f, ensure_ascii=False, indent=2)
print(f"✅ 完成转换,共生成 {len(nodes)} 个 memory 节点,{len(edges)} 条边")
print(f"📁 输出文件: {OUTPUT_FILE}")
配方3.5:MemOS集成与查询验证
🎯 目标
将转换后的Memory数据集成到MemOS系统,实现基于语义的智能检索。
🔗 MemOS连接器
建立与MemOS服务的稳定连接:
import memos
from memos.configs.embedder import EmbedderConfigFactory
from memos.configs.memory import TreeTextMemoryConfig
from memos.configs.mem_reader import SimpleStructMemReaderConfig
from memos.embedders.factory import EmbedderFactory
from memos.mem_reader.simple_struct import SimpleStructMemReader
from memos.memories.textual.tree import TreeTextMemory
from memos.configs.mem_os import MOSConfig
# 加载MemOS配置
config = TreeTextMemoryConfig.from_json_file("/root/Test/memos_config.json")
tree_memory = TreeTextMemory(config)
# 加载记忆数据
tree_memory.load("/root/Test")
# 执行语义搜索
results = tree_memory.search("段誉初遇神仙姐姐", top_k=5)
for result in results:
relativity = result.metadata.relativity if hasattr(result.metadata, 'relativity') else 0.0
print(f"相关度: {relativity:.3f}")
print(f"内容: {result.memory}")
print("---")
🔍 智能检索验证
通过多维度查询验证系统性能:
# 多类型查询测试
test_queries = [
"段誉初遇神仙姐姐",
"乔峰的身世之谜",
"虚竹的奇遇经历",
"丁春秋与无崖子的恩怨"
]
for query in test_queries:
print(f"\n🔍 查询: {query}")
results = tree_memory.search(query, top_k=3)
for i, result in enumerate(results, 1):
relativity = result.metadata.relativity if hasattr(result.metadata, 'relativity') else 0.0
print(f" {i}. 相关度: {relativity:.3f}")
print(f" 内容: {result.memory[:100]}...")
🎯 基于MemOS的创意扩展
恭喜!你已经掌握了MemOS的核心技术。现在让我们看看可以创造出什么令人兴奋的应用:
🕰️ 创意1:智能世界时间线系统
基于MemOS构建动态的武侠世界时间轴,让AI理解事件的因果关系:
# 示例:智能时间线管理
timeline_memory = {
"1094年": {
"events": ["萧峰身世之谜揭开", "聚贤庄大战"],
"consequences": ["江湖震动", "丐帮分裂"],
"affected_characters": ["萧峰", "阿朱", "段正淳"]
},
"1095年": {
"events": ["雁门关事件真相", "阿朱之死"],
"consequences": ["萧峰心境转变", "宋辽关系紧张"]
}
}
# AI可以回答:如果萧峰没有去雁门关,后续会如何发展?
🧠 创意2:动态Working Memory世界背景
利用MemCube的working memory功能,让世界背景随着剧情发展实时更新:
# 示例:动态世界状态管理
from memos.memories.textual.base import TextualMemoryItem
# 创建世界状态记忆项
world_state_memories = [
TextualMemoryItem(
memory="宋辽政治紧张程度达到0.8级别,边境冲突频发",
metadata={"type": "world_state", "category": "politics"}
),
TextualMemoryItem(
memory="当前江湖流传的绝世武功:九阳神功、易筋经",
metadata={"type": "world_state", "category": "martial_arts"}
),
TextualMemoryItem(
memory="少林与武当保持中立,丐帮内部出现分裂",
metadata={"type": "world_state", "category": "sect_relations"}
)
]
# 使用MemCube的文本记忆管理世界状态
mem_cube.text_mem.replace_working_memory(world_state_memories)
# 当萧峰做出重要决定时,自动更新工作记忆
current_working_memory = mem_cube.text_mem.get_working_memory()
🎮 创意3:MemOS驱动的互动文字游戏
终极创意:基于MemOS + MemCube + GPT-4o构建一个真正智能的单人文字冒险游戏!
# 游戏核心架构示例
class WuxiaTextGame:
def __init__(self, mos_config):
from memos.mem_os.main import MOS
self.world_memory = MOS(mos_config) # 世界记忆系统
self.character_cubes = {} # 每个NPC的MemCube
self.timeline_memories = [] # 时间线记忆列表
# 创建游戏主用户
self.world_memory.create_user("game_master")
def start_adventure(self, player_choice):
"""
玩家选择:
- 角色:萧峰/段誉/虚竹/自创角色
- 时间点:童年/青年/中年
- 地点:中原/大理/辽国
"""
return f"欢迎来到{player_choice.location}..."
def process_action(self, player_input):
"""
处理玩家的自然语言输入:
"我要去少林寺学武功"
"我想和萧峰结拜"
"我要阻止雁门关惨案"
"""
# 1. 理解玩家意图(使用MemOS的LLM功能)
intent_analysis = self.world_memory.chat(
query=f"分析玩家意图: {player_input}",
user_id="game_master"
)
# 2. 检索相关记忆
context = self.world_memory.search(
query=player_input,
user_id="game_master"
)
# 3. 计算行动后果(基于检索到的上下文)
consequences = self.predict_consequences(player_input, context)
# 4. 更新世界状态(添加新的记忆)
self.update_world_state(player_input, consequences)
# 5. 生成剧情发展
return self.generate_story(player_input, context, consequences)
def predict_consequences(self, player_input, context):
"""预测玩家行动的后果"""
query = f"基于以下背景:{context},预测玩家行动'{player_input}'的可能后果"
result = self.world_memory.chat(
query=query,
user_id="game_master"
)
return result
def update_world_state(self, player_input, consequences):
"""更新世界状态到MemOS记忆中"""
memory_content = f"玩家行动: {player_input}, 后果: {consequences}"
self.world_memory.add(
memory_content=memory_content,
user_id="game_master"
)
def generate_story(self, player_input, context, consequences):
"""生成故事发展"""
query = f"基于背景{context}和后果{consequences},为玩家行动'{player_input}'生成有趣的故事发展"
return self.world_memory.chat(
query=query,
user_id="game_master"
)
# 完整的使用示例
def create_wuxia_game():
"""创建完整的武侠文字游戏示例"""
from memos.configs.mem_os import MOSConfig
# 创建MemOS配置
mos_config = MOSConfig(
user_id="game_system",
chat_model={
"backend": "openai",
"config": {
"model_name_or_path": "gpt-4o",
"api_key": "YOUR_API_KEY",
"api_base": "https://api.openai.com/v1"
}
},
mem_reader={
"backend": "simple_struct",
"config": {
"llm": {
"backend": "openai",
"config": {
"model_name_or_path": "gpt-4o",
"api_key": "YOUR_API_KEY",
"api_base": "https://api.openai.com/v1"
}
}
}
},
enable_textual_memory=True
)
# 创建游戏实例
game = WuxiaTextGame(mos_config)
# 示例对话
response = game.process_action("我想在洛阳客栈寻找萧峰")
print(response)
return game
游戏玩法举例:
玩家:我是一个初出茅庐的少年,想去拜访萧峰
AI: 那时萧峰正在洛阳一带调查身世之谜,你在客栈偶遇了他...
萧峰看你年少,问道:"小兄弟,这么晚了还在外面游荡?"
玩家:我告诉他我想学武功,请他收我为徒
AI: 萧峰哈哈大笑:"我自己的身世都是一团迷雾,哪有资格做人师父?
不过既然相遇便是缘分,我可以教你几招防身..."
[你的武功等级 +1,与萧峰的关系 +5]
玩家:我想告诉萧峰他的身世真相
AI: 这是一个危险的选择!提前揭露身世可能改变整个故事走向...
确定要这么做吗?这将开启全新的剧情分支。
🌟 你的想象力就是边界!
基于MemOS,你可以创造:
- 📚 智能小说生成器 - AI根据你的设定自动创作
- 🎭 虚拟角色陪伴 - 和萧峰、段誉进行真实对话
- 🎨 交互式剧情创作 - 动态生成的故事世界
- 🎯 教育游戏平台 - 在游戏中学习历史和文学
- 🔮 预测性娱乐 - AI预测你的选择会如何影响剧情
关键在于:MemOS让AI拥有了真正的"记忆",可以:
- 🧠 记住所有历史事件和人物关系
- 🔄 根据玩家行动动态更新世界状态
- 🎯 生成符合逻辑的剧情发展
- 🌟 创造无限可能的故事分支
🎮 立即体验:互动文字游戏演示
想要亲手体验基于MemOS构建的文字游戏吗?我们提供了一个完整的演示项目,展示了如何将本章介绍的技术应用到实际的交互式文本生成中。
📦 演示特点
- 🎯 基于《天龙八部》: 使用本章处理的相同小说内容作为知识库
- 🔍 智能意图识别: 自动识别用户想要进行的操作类型
- 💬 多种交互模式: 支持故事续写、角色分析、假设情节、人物对话等
- 🧠 MemOS驱动: 展示真实的MemCube检索和上下文生成
🚀 立即尝试
👉 MemCube Interactive Text Game Demo - Hugging Face
该演示项目包含:
- ✅ 完整源代码: 展示MemOS各组件的实际使用方法
- ✅ 运行指南: 一步步教你如何部署和运行
- ✅ 技术说明: 详细解释实现原理和设计思路
- ✅ 可定制: 可以替换为你自己的文本内容
通过实际操作这个demo,你将更深入地理解本章介绍的MemOS技术如何在实际应用中发挥作用!
现在,释放你的创造力,用MemOS打造属于你的智能世界吧! 🚀