Building an Intelligent Novel Analysis System with MemOS
🆚 Why Choose MemOS? Traditional Methods vs MemOS Comparison
Before we start coding, let's see what problems MemOS actually solves:
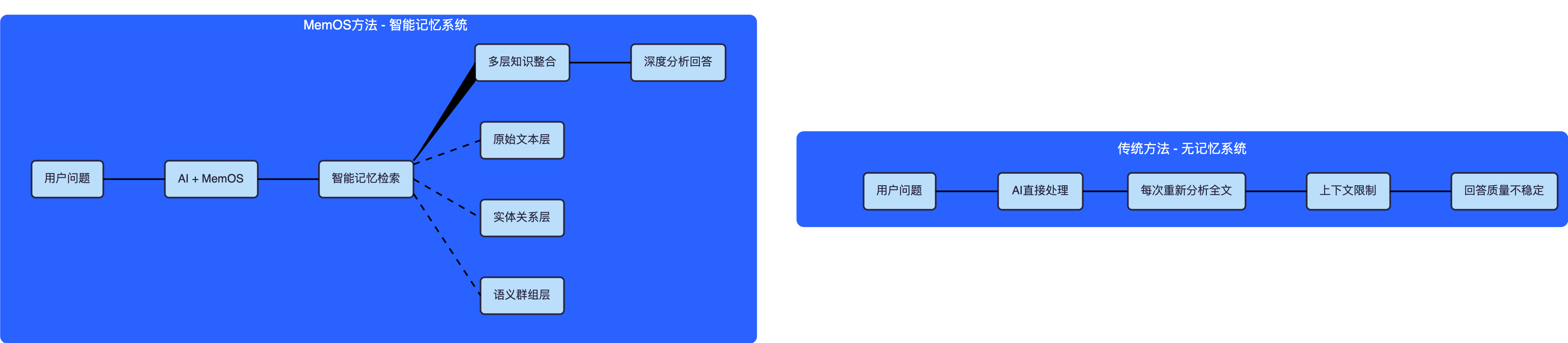
Actual Effect Comparison Example:
User asks: "How does the relationship between Xiao Feng and Duan Yu develop?"
| Traditional Method | MemOS Method |
|---|---|
| 🐌 Re-search relevant fragments in full text | ⚡ Direct retrieval from relationship layer |
| 😵 May miss key plot points | 🎯 Complete relationship development timeline |
| 📄 Can only answer based on partial text | 🧠 Analysis based on complete character profiles |
💡 Why Use MemOS Built-in Components?
Imagine you want to cook a dish, you can choose:
- 🔧 Make all seasonings yourself - Time-consuming and labor-intensive, hard to guarantee quality
- 🏪 Use professional seasoning brands - Time-saving and efficient, stable quality
MemOS is like a professional "seasoning brand" that has prepared for us:
- 🤖 Intelligent dialogue client - Automatically handles network issues, supports multiple AI models
- 🧠 Vectorization service - Specially optimized Chinese text understanding capabilities
- ⚙️ Configuration management - Simple and easy-to-use parameter settings
Learning Gains: Through this chapter, you will learn how to prioritize using mature component libraries like professional developers, rather than writing complex underlying code from scratch.
Chapter Introduction
This chapter will guide you to build an intelligent memory analysis system based on the novel "Demigods and Semi-Devils", implementing a complete conversion process from raw text to structured memory.
Core Technical Architecture:
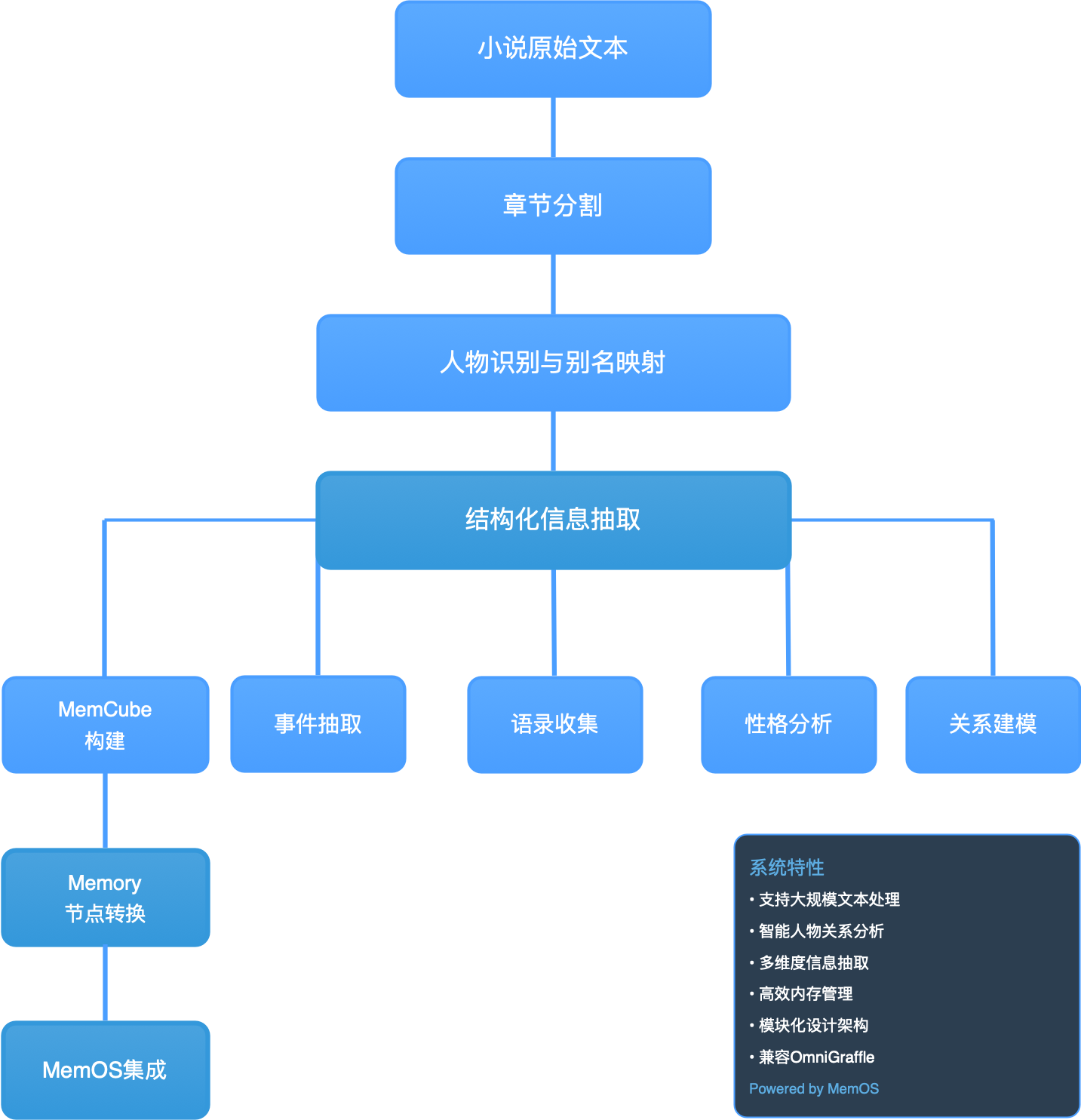
Data Processing Pipeline:
- Text Preprocessing → Chapter Segmentation → Structured Input
- AI-Driven Extraction → Character Modeling → MemCube Generation
- Format Conversion → Graph Structure Construction → MemOS Memory Repository
System Design Philosophy:
- This chapter provides a complete solution from unstructured text to intelligent memory systems
- Each recipe solves key technical problems in the data pipeline
- Supports large-scale text parallel processing and incremental updates
- Builds queryable and reasoning-capable intelligent memory networks
Environment Configuration
import requests
import json
import os
import pickle
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import re
from typing import Dict, List, Optional, Any, Set, Tuple
from dataclasses import dataclass, field
from enum import Enum
Recipe 3.0: Text Preprocessing and API Environment Configuration
🎯 Goal
Establish structured processing foundation for novel text, including chapter segmentation and AI service connection.
📖 Chapter Segmentation Algorithm
Use regular expressions to identify chapter titles and split long novels into processable fragments:
def extract_all_chapters(text: str, output_dir: str = "chapters"):
# Match positions of all "Chapter X" titles
pattern = r"(第[一二三四五六七八九十百千零〇两\d]+章)"
matches = list(re.finditer(pattern, text))
if not matches:
raise ValueError("No chapter titles found")
os.makedirs(output_dir, exist_ok=True)
for i in range(len(matches)):
start_idx = matches[i].start()
end_idx = matches[i+1].start() if i+1 < len(matches) else len(text)
chapter_title = matches[i].group()
chapter_number = i + 1 # Use natural numbers for numbering
chapter_text = text[start_idx:end_idx].strip()
filename = os.path.join(output_dir, f"chapter{chapter_number}.txt")
with open(filename, "w", encoding="utf-8") as f:
f.write(chapter_text)
print(f"✅ Saved: {filename} ({chapter_title})")
# Read the entire novel
with open("天龙八部.txt", "r", encoding="utf-8") as f:
full_text = f.read()
# Extract and save all chapters
extract_all_chapters(full_text)
🔧 API Client Configuration
Establish stable AI service connections, supporting model calls for different task types:
# JSON repair functionality configuration
try:
from json_repair import repair_json
HAS_JSONREPAIR = True
print("✓ jsonrepair library loaded, JSON repair functionality enabled")
except ImportError:
HAS_JSONREPAIR = False
print("⚠ jsonrepair library not installed, will use basic repair strategy")
def repair_json(text):
return text
class TaskType(Enum):
EVENT_EXTRACTION = "event_extraction"
class MemOSLLMClient:
"""Dialogue client - using MemOS makes AI calls simple and reliable"""
def __init__(self, api_key: str, api_base: str = "https://api.openai.com/v1", model: str = "gpt-4o"):
# 🔧 Step 1: Import MemOS intelligent components
from memos.llms.factory import LLMFactory
from memos.configs.llm import LLMConfigFactory
# 🎯 Step 2: Tell MemOS which AI model we want to use
llm_config_factory = LLMConfigFactory(
backend="openai", # Use OpenAI (also supports other vendors)
config={
"model_name_or_path": model, # Your chosen AI model
"api_key": api_key, # Your API key
"api_base": api_base, # API service address
"temperature": 0.8, # Creativity level
"max_tokens": 8192, # Maximum response length
"top_p": 0.9, # Response quality control
}
)
# 🚀 Step 3: Let MemOS help us create a dialogue client
# MemOS will automatically handle complex issues like network retries and connection pools
self.llm = LLMFactory.from_config(llm_config_factory)
print(f"✅ Dialogue client ready! Using model: {model}")
def call_api(self, messages: List[Dict], task_type: TaskType, timeout: int = 1800) -> Dict:
"""Method to chat with AI - it's that simple!"""
try:
response = self.llm.generate(messages)
return {
"status": "success", # Success!
"content": response, # AI's answer
"model_used": self.llm.config.model_name_or_path # Which model was used
}
except Exception as e:
# 😅 If there's an error, MemOS will tell us exactly what the problem is
return {
"status": "error",
"error": str(e),
"model_used": self.llm.config.model_name_or_path
}
🚀 Batch Processing Initialization
Establish chapter traversal mechanism, preparing for subsequent parallel processing:
# 🎯 Configure your AI assistant (using MemOS makes everything simple)
API_KEY = "YOUR_API_KEY" # 🔑 Fill in your OpenAI API key
API_BASE = "https://api.openai.com/v1" # 🌐 API service address (usually no need to change)
MODEL_NAME = "gpt-4o" # 🤖 Choose your preferred AI model
# 🚀 Create your dedicated AI assistant
api_client = MemOSLLMClient(
api_key=API_KEY,
api_base=API_BASE,
model=MODEL_NAME
)
# Now you have a smart, stable, easy-to-use AI assistant!
memcubes = {} # Global character memory repository
alias_to_name = {} # Alias to standard name mapping
chapter_folder = "chapters"
# Process in chapter order
chapter_files = sorted(
[os.path.join(chapter_folder, f) for f in os.listdir(chapter_folder)
if f.startswith("chapter") and f.endswith(".txt")],
key=lambda x: int(re.search(r'chapter(\d+)', x).group(1))
)
for chapter_file in chapter_files:
chapter_id = chapter_file.replace(".txt", "")
print(f"\n📖 Processing: {chapter_id}")
with open(chapter_file, "r", encoding="utf-8") as f:
content = f.read()
# Subsequent processing logic...
Recipe 3.1: AI-Driven Character Recognition and Alias Unification
🎯 Goal
Use AI to automatically identify characters in novels, establish alias mapping relationships, and initialize character memory containers.
🧠 Intelligent Character Recognition
Implement accurate character extraction and alias merging through carefully designed prompts:
@staticmethod
def extract_character_names_prompt(paragraph: str, alias_to_name: dict = None):
system_msg = (
"You are a novel character recognition expert. Please extract all explicitly mentioned characters from the following novel excerpt.\n"
"For each character, please mark the character's standard name (such as \"Qiao Feng\") and all titles, aliases, and references that appear in this excerpt (such as \"Beggar Gang Leader\", \"Leader Qiao\", \"that big man\").\n\n"
"Please return in the following JSON format:\n"
"[\n"
" {\n"
" \"name\": \"Qiao Feng\",\n"
" \"aliases\": [\"Beggar Gang Leader\", \"Leader Qiao\", \"that big man\"]\n"
" }\n"
"]\n\n"
"⚠️ Note:\n"
"1. Only include characters, not locations or organizations.\n"
"2. Multiple titles of the same character should be unified in the same entry.\n"
"3. Use standard JSON format for all fields. Do not include markdown symbols or comments.\n"
"4. If you cannot determine whether a title refers to a new character, you may temporarily keep it as a separate entry."
)
if alias_to_name:
system_msg += "\n\nThe following are known aliases corresponding to standard character names. Please try to categorize newly recognized titles under existing characters:\n"
alias_map_str = json.dumps(alias_to_name, ensure_ascii=False, indent=2)
system_msg += alias_map_str
return [
{"role": "system", "content": system_msg},
{"role": "user", "content": f"Novel excerpt as follows:\n{paragraph}"}
]
💾 MemCube Initialization and Alias Management
Create structured memory containers for each identified character:
def init_memcube(character_name: str, chunk_id: str):
"""Initialize character memory cube - contains all core fields"""
return {
"name": character_name,
"first_appearance": chunk_id,
"aliases": [character_name],
"events": [],
"utterances": [],
"speech_style": "",
"personality_traits": [],
"emotion_state": "",
"relations": []
}
# Execute character recognition and initialization
name_prompt = Prompt.extract_character_names_prompt(content, alias_to_name)
name_result = api_client.call_api(name_prompt, TaskType.EVENT_EXTRACTION, timeout=1800)
try:
extracted = json.loads(name_result.get("content", "").strip("```json").strip("```").strip())
except:
extracted = []
# Update character repository and alias mapping
for item in extracted:
std_name = item["name"]
aliases = item.get("aliases", [])
# Initialize or update MemCube
if std_name not in memcubes:
print(f"🆕 New character identified: {std_name}")
memcubes[std_name] = init_memcube(std_name, chapter_id)
memcubes[std_name]["aliases"] = []
# Merge alias lists
all_aliases = list(set(memcubes[std_name].get("aliases", []) + aliases))
memcubes[std_name]["aliases"] = all_aliases
# Build global alias mapping
for alias in [std_name] + aliases:
alias_to_name[alias] = std_name
Recipe 3.2: Structured Memory Content Extraction
🎯 Goal
Use AI to extract structured character information from novel text, including events, quotes, personality, emotions, and relationship networks.
🎭 Multi-dimensional Information Extraction Prompt
Design precise prompt templates to ensure AI returns standardized JSON data:
@staticmethod
def update_character_prompt(character_name: str, unfinished_events: list, paragraph: str):
return [
{
"role": "system",
"content": (
"You are a novel character modeling expert who will analyze a character's unfinished events and the latest novel excerpt.\n"
"Your task is to update the following fields:\n"
"- events: Event list (update status, add new events, including subfields event_id, action, motivation, impact, involved_entities, time, location, event, if_completed)\n"
"- Each event must include a unique \"event_id\", such as \"event_001\", \"event_002\", etc.\n"
"- utterances: Things said (with time or event number)\n"
"- speech_style: Speaking style (such as classical, direct, sarcastic, etc.)\n"
"- personality_traits: Personality (such as calm, impulsive)\n"
"- emotion_state: Current emotional state\n"
"- relations: List of relationships with others\n\n"
"Please pay special attention to the following requirements:\n"
"1. Please carefully judge whether existing unfinished events have ended in the new excerpt.\n"
"2. If an event has an ending or result, please mark its `if_completed` field as true.\n"
"3. If new events related to this character appear in the novel excerpt, please add new event entries.\n"
"Finally, please output the following JSON structure:\n"
"{\n"
" \"events\": [...],\n"
" \"utterances\": [...],\n"
" \"speech_style\": \"...\",\n"
" \"personality_traits\": [...],\n"
" \"emotion_state\": \"...\",\n"
" \"relations\": [...]\n"
"}\n\n"
"⚠️ Please note:\n"
"1. All field names must be wrapped in double quotes (JSON standard format).\n"
"2. Do not add comment symbols, additional explanations, or markdown symbols.\n"
"3. Only return complete JSON object, cannot be array or other formats.\n"
"4. If there is no content to fill, please use empty array [] or empty string \"\".\n"
)
},
{
"role": "user",
"content": (
f"Character name: {character_name}\n"
f"Current unfinished events as follows (JSON):\n{json.dumps(unfinished_events, ensure_ascii=False, indent=2)}\n\n"
f"Novel excerpt as follows:\n{paragraph}\n\n"
"Please return the character's updated information in the above format."
)
}
]
🔄 Intelligent Data Merging Algorithm
Implement event state tracking and incremental update mechanisms:
def get_unfinished_events(memcube: dict):
"""Get list of unfinished events - for context continuity"""
return [event for event in memcube.get("events", []) if not event.get("if_completed", False)]
def merge_events(old_events: list, new_events: list):
"""Intelligent event merging - handle status updates and new events"""
event_dict = {e["event_id"]: e for e in old_events}
for new_event in new_events:
eid = new_event["event_id"]
if eid in event_dict:
# Merge strategy: new fields take priority, preserve historical information
merged = event_dict[eid].copy()
for key, value in new_event.items():
if value not in [None, "", []]:
merged[key] = value
event_dict[eid] = merged
else:
event_dict[eid] = new_event # New events directly added
return list(event_dict.values())
def merge_unique_list(old: list, new: list):
"""List deduplication merging - maintain original order"""
combined = old + new
seen = set()
result = []
for item in combined:
if isinstance(item, dict):
key = json.dumps(item, sort_keys=True, ensure_ascii=False)
else:
key = str(item)
if key not in seen:
seen.add(key)
result.append(item)
return result
⚡ Parallel Processing Engine
Use thread pools to implement efficient batch character updates:
# Parallel update of all character states
with ThreadPoolExecutor(max_workers=8) as executor:
futures = {
executor.submit(update_memcube_for_character, name, memcube, content, chapter_id): name
for name, memcube in memcubes.items()
}
for future in as_completed(futures):
name = futures[future]
try:
name, updated, error = future.result()
if error or not updated:
print(f"⚠️ Update failed: {name} in {chapter_id} -> {error}")
continue
# Intelligently merge update results
memcube = memcubes[name]
memcube["events"] = merge_events(memcube["events"], updated.get("events", []))
memcube["utterances"].extend(updated.get("utterances", []))
if updated.get("speech_style"):
memcube["speech_style"] = updated["speech_style"]
memcube["personality_traits"] = merge_unique_list(
memcube["personality_traits"], updated.get("personality_traits", [])
)
if updated.get("emotion_state"):
memcube["emotion_state"] = updated["emotion_state"]
memcube["relations"].extend(updated.get("relations", []))
except Exception as e:
print(f"⚠️ Parallel execution exception: {name} -> {e}")
Recipe 3.3: Memory-Based Intelligent Reasoning System
🎯 Goal
Implement advanced functions such as novel plot reasoning, rationality assessment, and emotional analysis based on the constructed MemCube.
🔮 Plot Deduction Engine
Use complete character memory information for story development prediction:
@staticmethod
def speculate_event_outcome(character_name: str, memcube: dict, user_input: str):
"""Plot deduction based on character memory - generate novel-style narration"""
return [
{
"role": "system",
"content": (
"You are a novel script deduction expert.\n"
"You will receive complete JSON information of all characters (including event chains, personality, emotions, relationships, etc.) and a hypothetical plot proposed by the user.\n"
"Your task is to reasonably deduce possible story developments based on these characters' backgrounds, unfinished events, relationship networks, personality and motivations.\n"
"Please generate complete novel paragraph-style narration (not list, not JSON), describing how the story unfolds.\n"
"Note that the language style should be consistent with the original novel (such as classical martial arts style)."
)
},
{
"role": "user",
"content": (
f"Character name: {character_name}\n\n"
f"Character information as follows (JSON format):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"User's hypothetical plot as follows:\n{user_input}\n\n"
"Please deduce the story development based on the above information, return novel-style language narration, do not include any explanatory language or JSON."
)
}
]
@staticmethod
def evaluate_plot_reasonableness(character_name: str, memcube: dict, user_input: str):
"""Plot rationality analysis - judge plot credibility based on character logic"""
return [
{
"role": "system",
"content": (
"You are a novel character behavior rationality analysis expert.\n"
"You will receive complete JSON information of all characters (including event chains, personality, emotions, relationships, etc.) and a hypothetical plot proposed by the user.\n"
"Your task is:\n"
"1. Judge whether this plot conforms to the character's behavioral logic, personality traits, emotional state, and current background.\n"
"2. If unreasonable, please point out specific unreasonable aspects and explain the reasons.\n"
"3. If reasonable, please explain its rationality and briefly describe how this plot naturally occurs.\n\n"
"Return format:\n"
"- Rationality assessment: Reasonable / Unreasonable / Conditionally reasonable\n"
"- Analysis explanation: Detailed explanation of whether it conforms to character motivation, relationships and background\n"
"- Suggestions: If necessary, provide modification suggestions or more reasonable alternative expressions\n\n"
"Please answer in concise Chinese, do not generate novel text or JSON structure."
)
},
{
"role": "user",
"content": (
f"Character name: {character_name}\n\n"
f"Complete information of all characters as follows (JSON format):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"User's plot conception as follows:\n{user_input}\n\n"
"Please judge whether this plot conforms to the character's current state and logic, and explain the reasons."
)
}
]
🎭 Multi-dimensional Analysis Framework
Provide professional analysis tools such as emotional trajectory, conflict progression, and stance judgment:
@staticmethod
def emotion_trajectory_prompt(character_name: str, memcube: dict, user_input: str):
"""Emotional trajectory analysis - predict character emotional changes"""
return [
{
"role": "system",
"content": (
"You are a novel character emotional trajectory analysis expert.\n"
"You will receive complete information of a character (including events, personality, emotions, relationships, etc.) and a plot segment conceived by the user.\n"
"Please judge whether the character's emotions will change in this plot.\n\n"
"Your task is:\n"
"1. Judge whether the plot conception includes emotional changes.\n"
"2. If yes, please point out the emotion type and explain how this change is triggered.\n"
"3. If no, please explain why emotions remain stable.\n\n"
"Return format:\n"
"- Emotional change: Yes / No\n"
"- Current emotion: xxx\n"
"- Change reason: xxx\n"
"Please answer in concise Chinese."
)
},
{
"role": "user",
"content": (
f"Character name: {character_name}\n\n"
f"Complete information of this character as follows (JSON):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"User conceived plot as follows:\n{user_input}"
)
}
]
@staticmethod
def conflict_progression_prompt(character_name: str, memcube: dict, user_input: str):
"""Conflict evolution analysis - track the development of conflicts between characters"""
return [
{
"role": "system",
"content": (
"You are an expert in analyzing the evolution of conflicting relationships between novel characters.\n"
"You will receive complete data of a character (JSON format) and a plot conceived by the user.\n"
"Please judge whether this plot involves conflict progression with others.\n\n"
"Your task is:\n"
"1. Judge whether the conceived plot involves existing or potential conflict targets.\n"
"2. If yes, please judge whether the relationship changes (such as escalation, easing, or resolution).\n"
"3. Briefly describe the reason for the conflict change.\n\n"
"Return format:\n"
"- Opponent: xxx\n"
"- Current stage: xxx (such as: potential → escalation → easing → resolution)\n"
"- Change reason: xxx\n"
"Please answer in concise Chinese."
)
},
{
"role": "user",
"content": (
f"Character name: {character_name}\n\n"
f"Complete information of this character as follows (JSON):\n{json.dumps(memcube, ensure_ascii=False, indent=2)}\n\n"
f"User conceived plot as follows:\n{user_input}"
)
}
]
💡 Practical Application Example
# Load the constructed character memory repository
with open("memcubes1.json", "r", encoding="utf-8") as f:
memcubes = json.load(f)
character_name = "Duan Yu"
user_input = "What would happen if Duan Yu did not appear at the Sword Lake Palace martial arts competition?"
# Execute plot deduction
prompt = Prompt.speculate_event_outcome(character_name, memcubes[character_name], user_input)
response = api_client.call_api(prompt, TaskType.EVENT_EXTRACTION)
print(response.get("content", "❌ No return"))
Recipe 3.4: Embedding Model Optimization Configuration
🔄 Embedding Model Switching for Chinese Text Retrieval
Reason for Switching:
The original code uses the nomic-embed model for text vectorization, but this model is primarily optimized for English text and has the following issues when processing Chinese novel content:
- Limited Chinese semantic understanding: The nomic-embed-text model is mainly trained on English corpora, with weak semantic understanding and text relationship capture capabilities for Chinese language
- Insufficient retrieval accuracy: In Chinese novels like "Demigods and Semi-Devils", semantic similarity calculations for character, event, and relationship retrieval are not accurate enough
- Missing cultural background: Cannot well understand specific contexts such as martial arts, history, and culture in Chinese literary works
Recommended Replacement Solutions:
According to Mem0 official documentation and Chinese embedding model evaluation, the following configurations are recommended:
Option 1: OpenAI Embedding (Recommended)
config = {
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-large", # Supports multiple languages, excellent Chinese performance
"embedding_dims": 3072,
"api_key": "YOUR_OPENAI_API_KEY"
}
}
}
Advantages:
- Supports Chinese and English bilingual, excellent performance in Chinese text retrieval tasks
- Higher vector dimensions (3072), richer semantic representation
- Good performance in MTEB-zh evaluation
Option 2: M3E Model (Open Source Alternative)
config = {
"embedder": {
"provider": "huggingface",
"config": {
"model": "moka-ai/m3e-base", # Open source model specifically optimized for Chinese
"embedding_dims": 768
}
}
}
Advantages:
- Specifically trained for Chinese, superior to OpenAI ada-002 in Chinese text classification and retrieval
- Supports heterogeneous text retrieval, suitable for novel character relationships and event retrieval
- Completely open source, no API call fees
Option 3: Local Deployment
config = {
"embedder": {
"provider": "ollama",
"config": {
"model": "moka-ai/m3e-base",
"ollama_base_url": "http://localhost:11434"
}
}
}
Performance Comparison Data:
According to MTEB-zh evaluation results:
| Model | Chinese Text Classification Accuracy | Chinese Retrieval ndcg@10 | Advantage |
|---|---|---|---|
| nomic-embed | Not tested | Not tested | English optimization |
| OpenAI text-embedding-3-large | 0.6231 | 0.7786+ | Multilingual support |
| M3E-base | 0.6157 | 0.8004 | Chinese specialization |
Recipe 3.5: Memory Graph Structure Transformer
🎯 Goal
Convert MemCube data to MemOS-compatible Memory node format, building a queryable knowledge graph.
🏗️ Memory Node Generation
Convert character events and relationships to standardized Memory objects:
def create_memory_node(content: str, entities: list, key: str, memory_type: str = "fact") -> dict:
"""Create standardized Memory node"""
node_id = str(uuid.uuid4())
now = datetime.now().isoformat()
# Simulate embedding (in real applications, should use actual embedding service)
embedding = [0.1] * 768 # Example dimension
return {
"id": node_id,
"memory": content,
"metadata": {
"user_id": "",
"session_id": "",
"status": "activated",
"type": "fact",
"confidence": 0.99,
"entities": entities,
"tags": ["Event"] if "Event" in key else ["Relationship"],
"updated_at": now,
"memory_type": memory_type,
"key": key,
"sources": [],
"embedding": embedding,
"created_at": now,
"usage": [],
"background": ""
}
}
🔄 Batch Conversion Processing
Implement efficient MemCube to Memory conversion pipeline:
INPUT_FILE = "memcube_all.json"
OUTPUT_FILE = "memory_graph.json"
with open(INPUT_FILE, "r", encoding="utf-8") as f:
memcube_data = json.load(f)
nodes = []
edges = []
for character, data in memcube_data.items():
previous_event_id = None
# === Event sequence conversion ===
for event in data.get("events", []):
memory_text = f"{character} at {event.get('time')} in {event.get('location')}, because of {event.get('motivation')}, performed {event.get('action')}, the result was {event.get('impact')}."
entities = [character] + event.get("involved_entities", [])
node = create_memory_node(
content=memory_text,
entities=entities,
key=f"{character}'s event: {event.get('action')}"
)
nodes.append(node)
# Establish event temporal relationships
if previous_event_id:
edges.append({
"source": previous_event_id,
"target": node["id"],
"type": "FOLLOWS"
})
previous_event_id = node["id"]
# === Relationship network aggregation ===
relations_texts = []
seen = set()
for relation in data.get("relations", []):
name = relation.get("name") or relation.get("人物") or relation.get("character")
relation_text = relation.get("relation") or relation.get("relationship") or relation.get("关系")
if not name or not relation_text:
continue
dedup_key = (str(name), str(relation_text))
if dedup_key in seen:
continue
seen.add(dedup_key)
relations_texts.append(f"has {relation_text} relationship with {name}")
if relations_texts:
memory_text = f"{character} " + ", ".join(relations_texts) + "."
entities = [character]
node = create_memory_node(
content=memory_text,
entities=entities,
key=f"{character}'s relationship summary",
)
nodes.append(node)
# Save conversion results
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
json.dump({
"nodes": nodes,
"edges": edges
}, f, ensure_ascii=False, indent=2)
print(f"✅ Conversion completed, generated {len(nodes)} memory nodes, {len(edges)} edges")
print(f"📁 Output file: {OUTPUT_FILE}")
Recipe 3.5: MemOS Integration and Query Validation
🎯 Goal
Integrate converted Memory data into MemOS system, implementing semantic-based intelligent retrieval.
🔗 MemOS Connector
Establish stable connection with MemOS service:
import memos
from memos.configs.embedder import EmbedderConfigFactory
from memos.configs.memory import TreeTextMemoryConfig
from memos.configs.mem_reader import SimpleStructMemReaderConfig
from memos.embedders.factory import EmbedderFactory
from memos.mem_reader.simple_struct import SimpleStructMemReader
from memos.memories.textual.tree import TreeTextMemory
from memos.configs.mem_os import MOSConfig
# Load MemOS configuration
config = TreeTextMemoryConfig.from_json_file("/root/Test/memos_config.json")
tree_memory = TreeTextMemory(config)
# Load memory data
tree_memory.load("/root/Test")
# Execute semantic search
results = tree_memory.search("Duan Yu's first encounter with the fairy sister", top_k=5)
for result in results:
relativity = result.metadata.relativity if hasattr(result.metadata, 'relativity') else 0.0
print(f"Relevance: {relativity:.3f}")
print(f"Content: {result.memory}")
print("---")
🔍 Intelligent Retrieval Validation
Validate system performance through multi-dimensional queries:
# Multi-type query testing
test_queries = [
"Duan Yu's first encounter with the fairy sister",
"Qiao Feng's identity mystery",
"Xu Zhu's adventure experiences",
"The grudge between Ding Chunqiu and Wu Yazi"
]
for query in test_queries:
print(f"\n🔍 Query: {query}")
results = tree_memory.search(query, top_k=3)
for i, result in enumerate(results, 1):
relativity = result.metadata.relativity if hasattr(result.metadata, 'relativity') else 0.0
print(f" {i}. Relevance: {relativity:.3f}")
print(f" Content: {result.memory[:100]}...")
🎯 Creative Extensions Based on MemOS
Congratulations! You have mastered the core technologies of MemOS. Now let's see what exciting applications we can create:
🕰️ Creative 1: Intelligent World Timeline System
Build a dynamic martial arts world timeline based on MemOS, letting AI understand causal relationships between events:
# Example: Intelligent timeline management
timeline_memory = {
"1094": {
"events": ["Xiao Feng's identity mystery revealed", "Battle at Juxian Manor"],
"consequences": ["Martial world shaken", "Beggar Gang split"],
"affected_characters": ["Xiao Feng", "A'Zhu", "Duan Zhengchun"]
},
"1095": {
"events": ["Truth of Yanmen Pass incident", "A'Zhu's death"],
"consequences": ["Xiao Feng's mindset transformation", "Song-Liao tension"]
}
}
# AI can answer: What would happen if Xiao Feng didn't go to Yanmen Pass?
🧠 Creative 2: Dynamic Working Memory World Background
Use MemCube's working memory functionality to update world background in real-time as the plot develops:
# Example: Dynamic world state management
from memos.memories.textual.base import TextualMemoryItem
# Create world state memory items
world_state_memories = [
TextualMemoryItem(
memory="Song-Liao political tension reaches 0.8 level, border conflicts frequent",
metadata={"type": "world_state", "category": "politics"}
),
TextualMemoryItem(
memory="Current legendary martial arts in jianghu: Nine Yang Divine Skill, Muscle-Tendon Changing Classic",
metadata={"type": "world_state", "category": "martial_arts"}
),
TextualMemoryItem(
memory="Shaolin and Wudang maintain neutrality, Beggar Gang has internal split",
metadata={"type": "world_state", "category": "sect_relations"}
)
]
# Use MemCube's text memory to manage world state
mem_cube.text_mem.replace_working_memory(world_state_memories)
# When Xiao Feng makes important decisions, automatically update working memory
current_working_memory = mem_cube.text_mem.get_working_memory()
🎮 Creative 3: MemOS-Driven Text MUD Game
Ultimate Creative: Build a truly intelligent text adventure game based on MemOS + MemCube + GPT-4o!
# Game core architecture example
class WuxiaMUD:
def __init__(self, mos_config):
from memos.mem_os.main import MOS
self.world_memory = MOS(mos_config) # World memory system
self.character_cubes = {} # Each NPC's MemCube
self.timeline_memories = [] # Timeline memory list
# Create game master user
self.world_memory.create_user("game_master")
def start_adventure(self, player_choice):
"""
Player choice:
- Character: Xiao Feng/Duan Yu/Xu Zhu/Custom character
- Time point: Childhood/Youth/Middle age
- Location: Central Plains/Dali/Liao Kingdom
"""
return f"Welcome to {player_choice.location}..."
def process_action(self, player_input):
"""
Process player's natural language input:
"I want to go to Shaolin Temple to learn martial arts"
"I want to become sworn brothers with Xiao Feng"
"I want to prevent the Yanmen Pass tragedy"
"""
# 1. Understand player intent (using MemOS's LLM functionality)
intent_analysis = self.world_memory.chat(
query=f"Analyze player intent: {player_input}",
user_id="game_master"
)
# 2. Retrieve relevant memories
context = self.world_memory.search(
query=player_input,
user_id="game_master"
)
# 3. Calculate action consequences (based on retrieved context)
consequences = self.predict_consequences(player_input, context)
# 4. Update world state (add new memories)
self.update_world_state(player_input, consequences)
# 5. Generate plot development
return self.generate_story(player_input, context, consequences)
def predict_consequences(self, player_input, context):
"""Predict consequences of player actions"""
query = f"Based on the following background: {context}, predict possible consequences of player action '{player_input}'"
result = self.world_memory.chat(
query=query,
user_id="game_master"
)
return result
def update_world_state(self, player_input, consequences):
"""Update world state to MemOS memory"""
memory_content = f"Player action: {player_input}, consequences: {consequences}"
self.world_memory.add(
memory_content=memory_content,
user_id="game_master"
)
def generate_story(self, player_input, context, consequences):
"""Generate story development"""
query = f"Based on background {context} and consequences {consequences}, generate interesting story development for player action '{player_input}'"
return self.world_memory.chat(
query=query,
user_id="game_master"
)
# Complete usage example
def create_wuxia_game():
"""Create complete martial arts MUD game example"""
from memos.configs.mem_os import MOSConfig
# Create MemOS configuration
mos_config = MOSConfig(
user_id="game_system",
chat_model={
"backend": "openai",
"config": {
"model_name_or_path": "gpt-4o",
"api_key": "YOUR_API_KEY",
"api_base": "https://api.openai.com/v1"
}
},
mem_reader={
"backend": "simple_struct",
"config": {
"llm": {
"backend": "openai",
"config": {
"model_name_or_path": "gpt-4o",
"api_key": "YOUR_API_KEY",
"api_base": "https://api.openai.com/v1"
}
}
}
},
enable_textual_memory=True
)
# Create game instance
game = WuxiaMUD(mos_config)
# Example dialogue
response = game.process_action("I want to find Xiao Feng in Luoyang inn")
print(response)
return game
Game Gameplay Example:
Player: I am a young man new to jianghu, wanting to visit Xiao Feng
AI: At that time, Xiao Feng was investigating his identity mystery in the Luoyang area, you encountered him in an inn...
Xiao Feng looked at you, a young man, and asked: "Little brother, what are you doing out so late?"
Player: I tell him I want to learn martial arts and ask him to take me as disciple
AI: Xiao Feng laughed heartily: "My own identity is a mystery, how can I be qualified to be a teacher?
But since we met, it's fate. I can teach you a few moves for self-defense..."
[Your martial arts level +1, relationship with Xiao Feng +5]
Player: I want to tell Xiao Feng the truth about his identity
AI: This is a dangerous choice! Revealing identity prematurely might change the entire story direction...
Are you sure you want to do this? This will open a completely new plot branch.
🌟 Your Imagination is the Limit!
Based on MemOS, you can create:
- 📚 Intelligent novel generator - AI automatically creates stories based on your settings
- 🎭 Virtual character companionship - Have real conversations with Xiao Feng and Duan Yu
- 🎨 Interactive plot creation - Multi-person collaborative dynamic story world
- 🎯 Educational game platform - Learn history and literature through games
- 🔮 Predictive entertainment - AI predicts how your choices will affect the plot
The key is: MemOS gives AI true "memory", enabling it to:
- 🧠 Remember all historical events and character relationships
- 🔄 Dynamically update world state based on player actions
- 🎯 Generate logically consistent plot developments
- 🌟 Create unlimited possible story branches
Now, unleash your creativity and build your intelligent world with MemOS! 🚀