What is MemOS?
As LLMs advance to handle complex tasks — like multi-turn dialogue, long-term planning, decision-making, and personalized user experiences — their ability to structure, manage, and evolve memory becomes critical for achieving true long-term intelligence and adaptability.
However, most mainstream LLMs still rely heavily on static parametric memory (model weights). This makes it difficult to update knowledge, track memory usage, or accumulate evolving user preferences. The result? High costs to refresh knowledge, brittle behaviors, and limited personalization.
MemOS solves these challenges by redefining memory as a core, modular system resource with a unified structure, lifecycle management, and scheduling logic. It provides a Python-based layer that sits between your LLM and external knowledge sources, enabling persistent, structured, and efficient memory operations.
With MemOS, your LLM can retain knowledge over time, manage context more robustly, and reason with memory that's explainable and auditable — unlocking more intelligent, reliable, and adaptive AI behaviors.
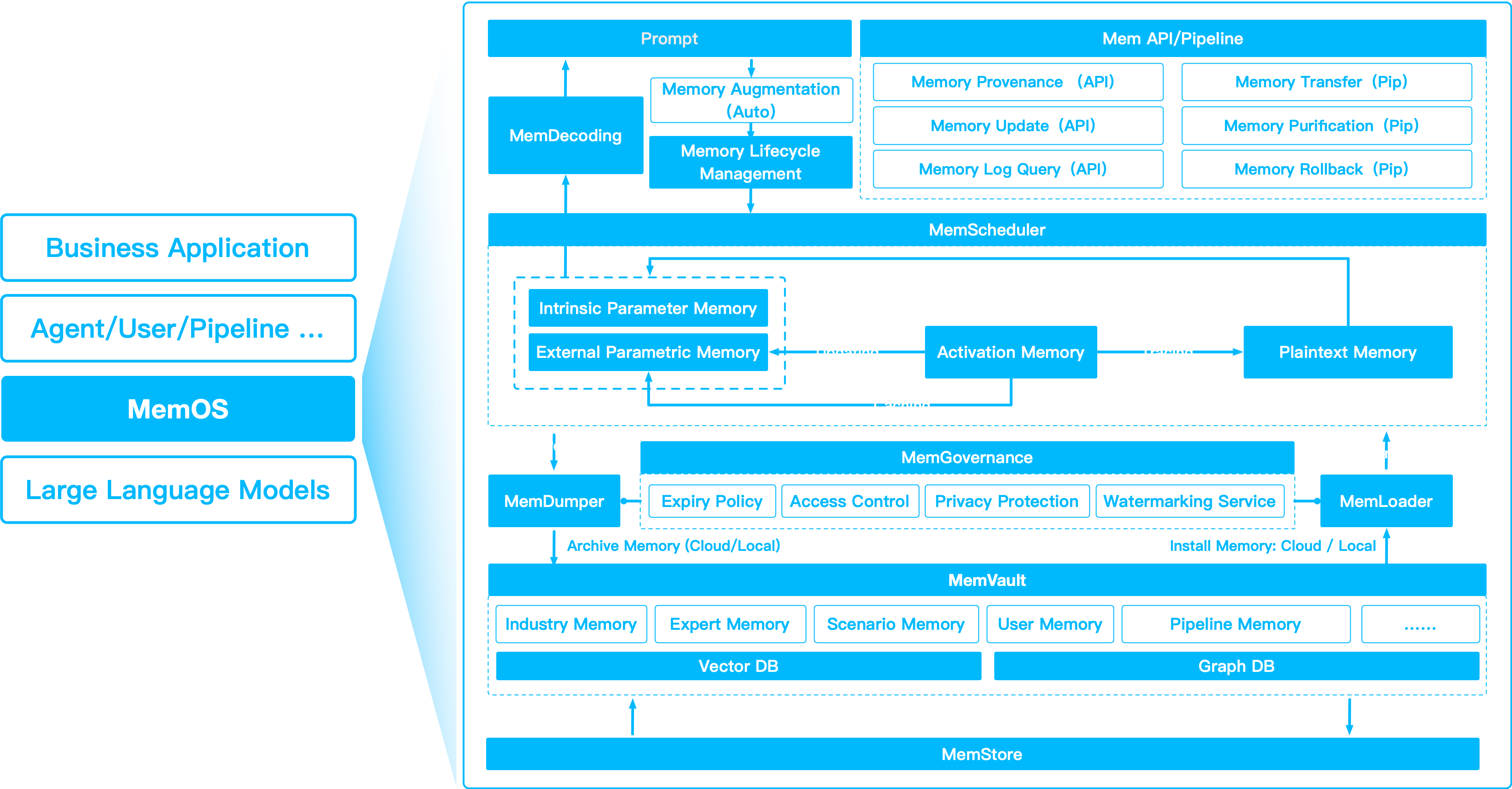
MemOS helps bridge the gap between static parametric weights and dynamic, user-specific memory. Think of it as your agent's "brain", with plug-and-play modules for text, graph, and activation memory.
Why do we need a Memory OS?
Modern LLMs are powerful—but static. They rely heavily on parametric memory (the weights) that is hard to inspect, update, or share. Typical vector search (RAG) helps retrieve external facts, but lacks unified governance, lifecycle control, or cross-agent sharing.
MemOS changes this. Think of it like an OS for memory: just as an operating system schedules CPU, RAM, and files, MemOS schedules, transforms, and governs multiple memory types — from parametric weights to ephemeral caches to plaintext, traceable knowledge.
MemOS helps your LLM evolve, by blending parametric, activation, and plaintext memory into a living loop.
Core Building Blocks
MemCubes
Flexible containers that hold one or more memory types. Each user, session, or agent can have its own MemCube — swappable, reusable, and traceable.
Memory Lifecycle
Each memory unit can flow through states like:
- Generated → Activated → Merged → Archived → Frozen
Every step is versioned with provenance tracking and audit logs. Old memories can be "time-machined" back to prior versions for recovery or counterfactual simulations.
Operation & Governance
Modules like:
- MemScheduler — dynamically transforms memory types for optimal reuse.
- MemLifecycle — manages state transitions, merging, and archiving.
- MemGovernance — handles access control, redaction, compliance, and audit trails.
Every memory unit carries full provenance metadata, so you can audit who created, modified, or queried it.
Multi-Perspective Memory
MemOS blends three memory forms in a living loop:
| Type | Description | Use Case |
|---|---|---|
| Parametric | Knowledge distilled into model weights | Evergreen skills, stable domain facts |
| Activation | KV-caches and hidden states for inference reuse | Fast multi-turn chat, low-latency generation |
| Plaintext | Text, docs, graphs, vector chunks, user-visible facts | Semantic search, evolving, explainable memory |
Over time:
- Hot plaintext memories can be distilled into parametric weights.
- Stable context is promoted to KV-cache for rapid injection.
- Cold or outdated knowledge can be demoted for auditing.
What makes MemOS different?
- Hybrid retrieval — symbolic & semantic, vector + graph.
- Multi-agent & multi-user graphs — private and shared.
- Provenance & audit trail — every memory unit is governed and explainable.
- Automatic KV-cache promotion for stable context reuse.
- Lifecycle-aware scheduling — no more stale facts or bloated weights.
Who is it for?
- Conversational agents needing multi-turn, evolving memory
- Enterprise copilots handling compliance, domain updates, and personalization
- Multi-agent systems collaborating on a shared knowledge graph
- AI builders wanting modular, inspectable memory instead of black-box prompts
Key Takeaway
MemOS upgrades your LLM from "just predicting tokens" to an intelligent, evolving system that can remember, reason, and adapt — like an operating system for your agent's mind.
With MemOS, your AI doesn't just store facts — it grows.
Key Features
- Modular Memory Architecture: Support for textual, activation (KV cache), and parametric (adapters/LoRA) memory.
- MemCube: Unified container for all memory types, with easy load/save and API access.
- MOS: Memory-augmented chat orchestration for LLMs, with plug-and-play memory modules.
- Graph-based Backends: Native support for Neo4j and other graph DBs for structured, explainable memory.
- Easy Integration: Works with HuggingFace, Ollama, and custom LLMs.
- Extensible: Add your own memory modules or backends.
Overview
Welcome to the official documentation for MemOS – a Python package designed to empower large language models (LLMs) with advanced, modular memory capabilities.
Core Concepts
MemOS treats memory as a first-class citizen. Its core design revolves around how to orchestrate, store, retrieve, and govern memory for your LLM applications.