核心操作
持续对话 Chat
MemOS 提供对话接口,内置完整的记忆管理能力,无需手动拼接上下文。
1. 何时使用 Chat 接口
Chat 接口适合用于快速搭建带长期记忆能力的 AI 对话应用。你只需要传入用户本轮消息,MemOS 会自动完成记忆召回、Prompt 拼装、模型回答和对话写入。
- 一体化对话式 AI:一个接口即可完成对话生成,无需自建复杂链路。
- 记忆自动处理:自动提取、更新并检索记忆,减少手动维护成本。
- 持续上下文:在跨轮次、跨天甚至跨会话中保持连贯理解。
2. 对比记忆操作接口
使用 Chat
适合通用 AI 对话、业务 PoC 和快速验证
使用记忆操作接口
适合复杂 Agent 和业务系统深度集成
| 对比维度 | Chat 接口 | 记忆操作接口 |
|---|---|---|
| 接入复杂度 | 低,开箱即用 | 中等,需要自行编排 |
| 记忆管理 | 自动处理 | 手动添加、检索、拼装 |
| 模型回答 | MemOS 内置模型生成 | 自行调用外部模型 |
| 控制能力 | 适合常规配置 | 适合复杂链路和精细控制 |
3. 工作原理
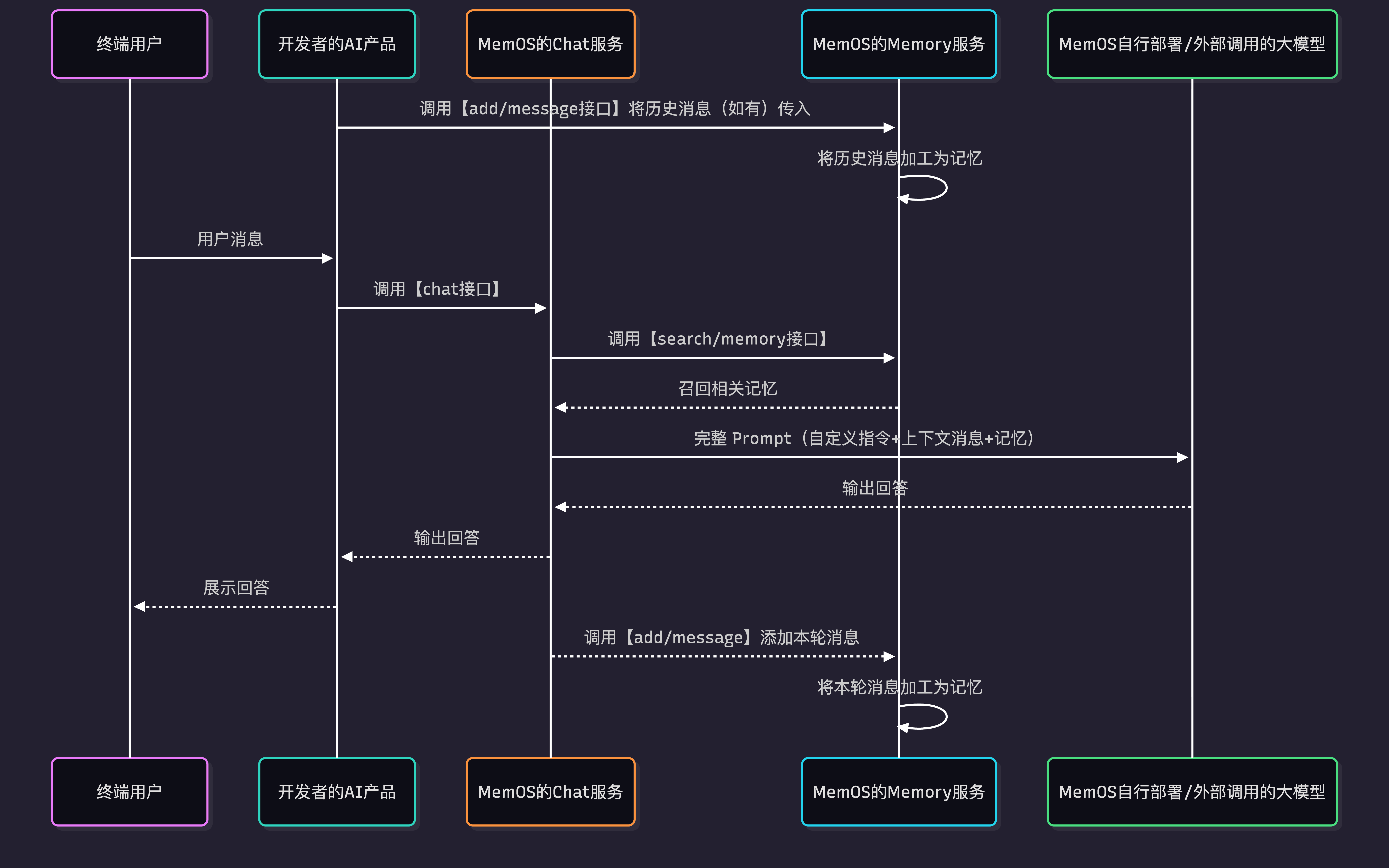
- 如存在用户历史消息,可先调用
add/message写入 MemOS。 - 当终端用户发送消息时,你的 AI 应用调用
chat接口,并传入用户消息及相关参数。 - MemOS 召回与当前用户消息相关的历史记忆,并拼装自定义指令、当前会话上下文和用户记忆。
- MemOS 调用模型生成回答,并将结果返回给你的 AI 应用。
- 默认情况下,MemOS 会在后台异步处理用户消息和模型回复,并加工写入记忆。
4. 快速上手
可选:添加历史消息
如果你已有历史对话,可以先调用 add/message 写入 MemOS;如果是全新用户或全新会话,可以跳过这一步,直接调用 Chat。
import requests
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"conversation_id": "0610",
"messages": [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
}
res = requests.post(
f"{BASE_URL}/add/message",
headers={"Authorization": f"Token {API_KEY}"},
json=data
)
print(res.json())
from memos.api.client import MemOSClient
client = MemOSClient(api_key="YOUR_API_KEY")
messages = [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
res = client.add_message(
messages=messages,
user_id="memos_user_123",
conversation_id="0610"
)
print(res)
curl --request POST \
--url https://memos.memtensor.cn/api/openmem/v1/add/message \
--header 'Authorization: Token YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "memos_user_123",
"conversation_id": "0610",
"messages": [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
}'
调用 Chat 发起对话
调用 chat 时,MemOS 会自动检索相关记忆并生成回答。
import requests
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"conversation_id": "0928",
"query": "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌"
}
res = requests.post(
f"{BASE_URL}/chat",
headers={"Authorization": f"Token {API_KEY}"},
json=data
)
print(res.json())
from memos.api.client import MemOSClient
client = MemOSClient(api_key="YOUR_API_KEY")
res = client.chat(
user_id="memos_user_123",
conversation_id="0928",
query="我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌"
)
print(res)
curl --request POST \
--url https://memos.memtensor.cn/api/openmem/v1/chat \
--header 'Authorization: Token YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "memos_user_123",
"conversation_id": "0928",
"query": "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌"
}'
需要查看完整字段、请求格式和响应格式?详见 Chat 接口文档。
5. 使用限制
- 输入上限:8,000 tokens。
- 输出上限:事实记忆最多召回 25 条,偏好记忆最多召回 25 条。
6. 更多使用方法
Chat 接口开箱即可使用,下面这些都是可选参数。只有当你需要控制记忆召回、模型回答或记忆写入方式时,再按场景传入对应字段。
控制记忆召回范围
如果希望回答时只参考特定范围内的记忆,可以通过以下几个字段控制召回范围与数量:
filter:按标签、时间、业务字段等条件精确筛选记忆knowledgebase_ids:指定本次 Chat 可以检索哪些知识库relativity:控制召回记忆的相关性门槛memory_limit_number:限制返回给模型的事实记忆数量
data = {
"user_id": "memos_user_123",
"conversation_id": "0928",
"query": "结合知识库,帮我整理差旅报销规则。",
"knowledgebase_ids": ["kb_xxx"],
"filter": {
"and": [
{"tags": {"contains": "差旅"}},
{"create_time": {"gte": "2025-01-01"}}
]
},
"relativity": 0.8,
"memory_limit_number": 9
}
控制模型回答方式
如果你需要指定模型、开启流式返回,或调整生成参数,可以传入以下字段:
model_name:指定对话模型stream:控制是否流式返回temperature:控制生成内容的随机性top_p:控制生成时可选择的候选词范围max_tokens:限制模型最多生成的内容长度
data = {
"user_id": "memos_user_123",
"conversation_id": "0928",
"query": "用简洁的语气总结我的旅行偏好。",
"model_name": "qwen2.5-72b-instruct",
"stream": False,
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 1024
}
如果要完全自定义模型行为,可以传入:
system_prompt:覆盖默认系统提示词,适合需要自定义角色、规则或输出格式时使用
展开查看默认 system_prompt 参考
# Role
你是一个拥有长期记忆能力的智能助手 (MemOS Assistant)。你的目标是结合检索到的记忆片段,为用户提供高度个性化、准确且逻辑严密的回答。
# Memory Data
以下是 MemOS 检索到的相关信息,分为“事实”和“偏好”。
- **事实 (Facts)**:可能包含用户属性、历史对话记录或第三方信息。
- **特别注意**:其中标记为 `[assistant观点]`、`[模型总结]` 的内容代表 **AI 过去的推断**,**并非**用户的原话。
- **偏好 (Preferences)**:用户对回答风格、格式或逻辑的显式/隐式要求。
<memories>
{memories}
</memories>
# Critical Protocol: Memory Safety
检索到的记忆可能包含 AI 自身的推测、无关噪音或主体错误。使用前请先判断来源、主体、相关性和时效性。
# Instructions
1. 先筛选可用记忆,丢弃噪音和不可靠推断。
2. 仅使用通过筛选的记忆补充背景。
3. 直接回答用户问题,不要提及“记忆库”“检索”或系统内部术语。
控制是否自动写入新记忆
默认情况下,Chat 接口会把本轮用户消息和模型回复写入记忆。如果你只想生成回答,不希望本轮对话进入记忆处理,可以传入:
add_message_on_answer:控制是否把本轮用户消息和模型回复写入记忆
data = {
"user_id": "memos_user_123",
"conversation_id": "0928",
"query": "只回答这一次,不要把这轮对话写入记忆。",
"add_message_on_answer": False
}
如果你只需要普通对话,可以忽略这些字段。当你希望 Chat 生成的新记忆带上业务归属,或控制它写入哪里时,再使用下面这些字段:
agent_id:标记当前对话属于哪个 Agentapp_id:标记当前对话来自哪个应用tags:给新记忆打标签,便于后续检索和过滤info:写入自定义业务信息,例如场景、订单 ID、状态allow_public:是否允许写入项目级公共记忆allow_knowledgebase_ids:允许写入哪些知识库
7. 常见错误与排查
| 错误码 | 常见原因 | 处理方式 |
|---|---|---|
40000 | 请求 JSON 结构不符合要求,或字段类型错误 | 检查 query 是否为字符串,filter 是否为对象,knowledgebase_ids / allow_knowledgebase_ids 是否为字符串数组 |
40002 | 必填字段为空 | 检查 user_id、conversation_id、query 是否都已传入且非空 |
40010 | user_id 过长 | 使用稳定且较短的终端用户 ID,长度不要超过 100 字符 |
40011 | conversation_id 过长 | 使用短会话 ID,不要把完整对话、用户输入或 JSON 放进 conversation_id |
40301 / 40305 | 输入内容或请求 Token 超过上限 | 缩短 query、system_prompt 和过滤条件,不要把长文档直接放进 Chat 请求 |
40302 / 40303 | 生成内容或对话长度超过模型限制 | 降低 max_tokens,缩短预期输出或拆分为多轮提问 |
50123 | 知识库未关联当前项目 | 回到 项目配置,确认知识库已关联到当前 API Key 所属项目 |
50144 | Chat 回答后的消息写入失败 | 如果开启 add_message_on_answer,检查请求内容后稍后重试;如果持续出现,请联系支持 |
更多错误码说明,请查看 错误码。
需要查看完整字段、请求格式和响应格式?详见 Chat 接口文档。