核心操作
Add Feedback
添加用户自然语言反馈,MemOS 将自动更新记忆。
1. 何时添加反馈?
MemOS 反馈机制用于接收用户对模型回答、知识内容或历史记忆的自然语言反馈,并自动完成记忆校正与更新。你不需要手动定位具体记忆条目,只需要把用户反馈传入 add/feedback。
| 对比维度 | 自然语言反馈 | 定点修改记忆 |
|---|---|---|
| 使用方式 | 用自然语言描述问题或修正信息 | 直接指定某条 memory 进行编辑 |
| 用户门槛 | 低,适合非技术用户 | 较高,通常由开发者或管理员操作 |
| 系统参与度 | 系统自动解析、定位、关联更新 | 人工主导更新 |
| 适用场景 | 对话纠错、知识过期、业务规则变更 | 精确修订、结构化维护 |
2. 关键参数
- 反馈内容(feedback_content):用户对模型回答、知识内容或记忆结果的自然语言反馈。
- 用户标识(user_id):反馈内容所关联的用户唯一标识符。
- 会话标识(conversation_id):反馈内容所关联的会话唯一标识符,用于补充上下文。
- 知识库范围(allow_knowledgebase_ids):反馈产生的新记忆允许写入的知识库列表。
3. 工作原理
以 Chatbot 场景为例,用户可以在模型回答下方点击“反馈错漏”,填写对本次回答的反馈并提交。
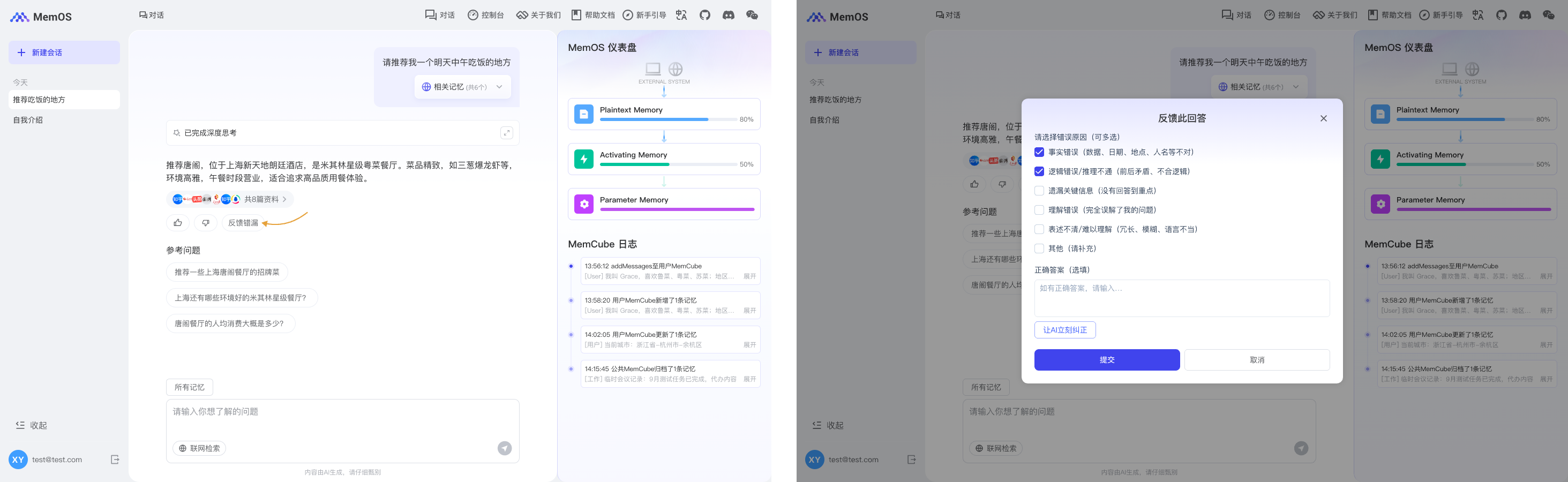
根据反馈内容,后端完成一次 MemOS add/feedback 接口调用,触发记忆更新。
- 有效性分析:结合当前会话上下文解析反馈内容,判断是否为有效信息、是否与对话内容相关。
- 更新类型识别:将反馈更新请求分类为关键词替换或语义更新。
- 更新记忆:写入新记忆,并对存在冲突、过时或被纠正的已有记忆进行更新或覆盖。
4. 快速上手
语义更新知识库记忆
当企业政策、知识库内容或业务规则发生变化时,可以直接把用户的自然语言反馈传入 MemOS,让系统生成新的高权重记忆。
提交自然语言反馈
财务主管在会话中反馈:办公类软件的采购上限应为 600 元,而不是 800 元。
import requests
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"conversation_id": "memos_feedback_conv",
"feedback_content": "办公类软件的采购上限是600元,而不是800元。",
"allow_knowledgebase_ids": ["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
}
res = requests.post(
f"{BASE_URL}/add/feedback",
headers={"Authorization": f"Token {API_KEY}"},
json=data
)
print(res.json())
from memos.api.client import MemOSClient
client = MemOSClient(api_key="YOUR_API_KEY")
res = client.add_feedback(
user_id="memos_user_123",
conversation_id="memos_feedback_conv",
feedback_content="办公类软件的采购上限是600元,而不是800元。",
allow_knowledgebase_ids=["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
)
print(res)
curl --request POST \
--url https://memos.memtensor.cn/api/openmem/v1/add/feedback \
--header 'Authorization: Token YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "memos_user_123",
"conversation_id": "memos_feedback_conv",
"feedback_content": "办公类软件的采购上限是600元,而不是800元。",
"allow_knowledgebase_ids": ["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
}'
检索验证更新结果
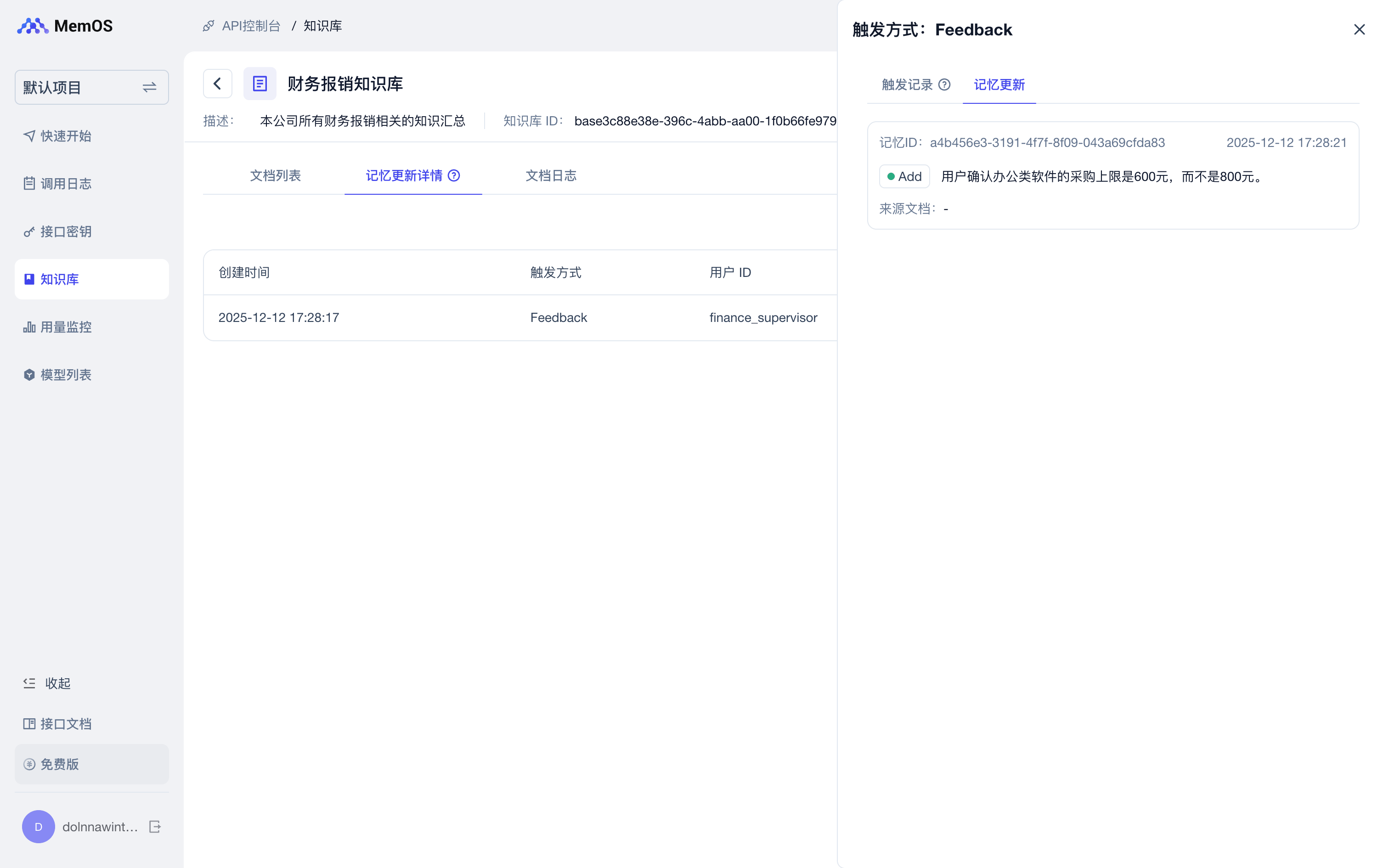
反馈处理完成后,任意其他用户搜索【软件报销制度】时,获取一条新增高权重记忆【办公类软件的采购上限为600元,而不是800元】。
import requests
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"conversation_id": "memos_feedback_check",
"query": "帮我查一下软件采购报销额度。",
"knowledgebase_ids": ["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
}
res = requests.post(
f"{BASE_URL}/search/memory",
headers={"Authorization": f"Token {API_KEY}"},
json=data
)
print(res.json())
from memos.api.client import MemOSClient
client = MemOSClient(api_key="YOUR_API_KEY")
res = client.search_memory(
user_id="memos_user_123",
conversation_id="memos_feedback_check",
query="帮我查一下软件采购报销额度。",
knowledgebase_ids=["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
)
print(res)
curl --request POST \
--url https://memos.memtensor.cn/api/openmem/v1/search/memory \
--header 'Authorization: Token YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "memos_user_123",
"conversation_id": "memos_feedback_check",
"query": "帮我查一下软件采购报销额度。",
"knowledgebase_ids": ["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
}'
输出结果
"memory_detail_list": [
{
"id": "8a4f3d2e-c417-4e53-bc25-54451abd5ac8",
"memory_key": "软件采购报销制度(试行版)",
"memory_value": "该制度要求办公类软件的采购上限为800元,适用于文档编辑和表格处理。",
"memory_type": "LongTermMemory",
"conversation_id": "default_session",
"relativity": 0.8931847
},
{
"id": "a72a04d1-d7ba-4ebd-9410-0097bfa6c20d",
"memory_key": "办公软件采购上限",
"memory_value": "用户确认办公类软件的采购上限是600元,而不是800元。",
"memory_type": "WorkingMemory",
"conversation_id": "memos_feedback_conv",
"relativity": 0.7196722
}
]
控制台-知识库中也会展示通过自然语言交互更正或补全的知识库记忆。
关键词替换记忆
如果用户明确指出某个名称、规则或字段需要整体替换,也可以直接用自然语言描述替换意图。
data = {
"user_id": "memos_user_123",
"conversation_id": "memos_feedback_conv",
"feedback_content": "从现在开始我改名了,把用户1号统一替换为用户2号",
"allow_knowledgebase_ids": ["basee5ec9050-c964-484f-abf1-ce3e8e2aa5b7"]
}
5. 常见错误与排查
| 错误码 | 常见原因 | 处理方式 |
|---|---|---|
40000 | 请求 JSON 结构不符合要求,或字段类型错误 | 检查 feedback_content 是否为字符串,allow_knowledgebase_ids 是否为字符串数组 |
40002 | 必填字段为空 | 检查 user_id、conversation_id、feedback_content 是否都已传入且非空 |
40011 | conversation_id 过长 | 使用短 ID,不要把完整对话、用户输入或 JSON 放进 conversation_id |
40305 | 单次输入超过 token 上限 | 缩短反馈内容,保留需要修正的关键信息 |
40309 | 单位时间输入 token 超限 | 降低反馈写入并发,分批重试 |
50123 | 知识库未关联当前项目 | 回到 项目配置,确认知识库已关联到当前 API Key 所属项目 |
50145 | 保存反馈并写入记忆失败 | 检查请求内容后稍后重试;如果持续出现,请联系支持 |
需要查看完整字段、请求格式和响应格式?详见 Add Feedback 接口文档。