持续对话Chat
MemOS 提供对话接口,内置了完整的记忆管理能力,您无需再手动拼接上下文。
1. 何时使用 Chat 接口
MemOS 提供的 Chat 接口支持端到端的对话消息输入输出,让您能够实现:
- 一体化对话式AI:仅需调用一个接口传入用户本次对话消息即可完成对话,无需自建复杂链路。
- 记忆自动处理:MemOS 会自动提取、更新并检索记忆,无需手动维护,不会漏掉重要细节。
- 持久“上下文”:在跨轮次、跨天甚至跨会话中保持连贯理解,让模型持续“记住”用户。
2. 工作原理
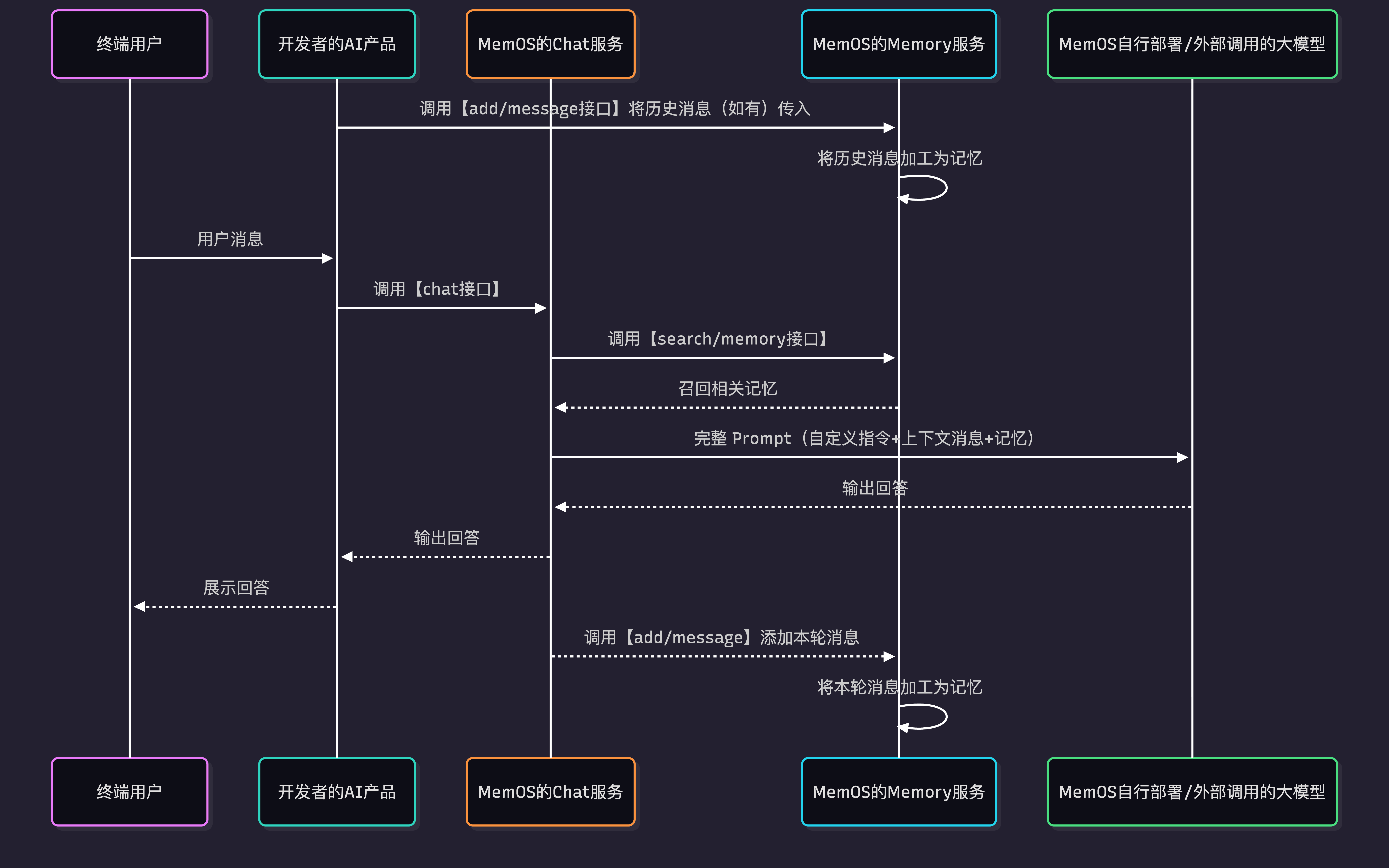
上图展示了终端用户、您的 AI 应用与 MemOS 的完整交互流程:
- 如存在用户历史消息,您可先调用 add/message 接口写入 MemOS。
- 当终端用户发送消息时,您的 AI 应用调用 Chat 接口,并传入用户消息及相关参数。
- MemOS 接收到请求后,会依次完成以下处理:
- 召回与当前用户消息相关的历史记忆;
- 将自定义指令、当前会话上下文与召回的用户记忆拼接为完整 Prompt;
- 调用大模型生成回答,并将结果返回给您的 AI 应用。
- 您的 AI 应用接收回答后,将内容展示给终端用户。
- 同时,MemOS 会在后台默认以异步方式处理用户消息和模型回复,加工并写入记忆。
3. 快速上手
添加历史消息
import os
import requests
import json
# 替换成你的 MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"conversation_id": "0610",
"messages": [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/add/message"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
对话
import os
import requests
import json
# 替换成你的 MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"user_id": "memos_user_123",
"query": "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌",
"conversation_id": "0928"
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/chat"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
4. 使用限制
接口输入上限: 8,000 tokens。
接口输出上限:检索记忆条数——事实记忆25条;偏好记忆25条。
5. 更多功能
除了一键复制上述快速开始代码,本接口还提供了丰富的其他可配置参数,您在使用过程中可参考以下字段的解释来调用 Chat 接口实现对话。
有关 API 字段、格式等信息的完整列表,详见Chat 接口文档。
筛选召回的记忆
| 功能 | 字段 | 说明 |
|---|---|---|
| 记忆过滤器 | filter | 支持自定义结构化查询条件,精确筛选记忆,详见记忆过滤器。 |
| 召回偏好记忆 | include_preferencepreference_limit_number | 偏好记忆是 MemOS 基于用户历史消息分析生成的用户偏好信息。 开启后,可在检索结果中召回用户偏好记忆,“更懂用户”。 |
| 检索指定知识库 | knowledgebase_ids | 指定本次检索可使用的项目关联知识库范围,详见知识库。 |
调整模型回答
| 功能 | 字段 | 说明 & 可选值 |
|---|---|---|
| 选定模型 | model_name | 当前 MemOS 提供了三种可以指定回答的模型,您可以在控制台 - 模型列表查阅详细的模型介绍。可选的模型名称: * qwen2.5-72b-instruct(默认) * qwen3-32b * deepseek-r1 |
| 自定义系统提示词 | system_prompt | 支持开发者自定义系统提示词。默认 MemOS 自带的指令。 |
| 流式/非流式回答 | stream | MemOS 提供流式和非流式两种回答方式,您可以根据自己的需求选择任意一种回答方式。 在调用接口时传入 stream=true 或者 false即可。默认的输出方式为:非流式输出。 |
| 关键参数 | temperature | 控制模型生成内容的随机性。值越低,回答越稳定、越接近固定答案;值越高,回答越发散、多样。 可选值范围:0-2,默认的温度值:0.7 |
| top_p | 控制模型生成内容时可选择的候选词范围。值越小,可选范围越窄,输出更收敛;值越大,可选范围越广,输出更多样。 可选值范围:0-1,默认值:0.95 | |
| max_tokens | 限制模型最多生成的内容长度。数值越大,允许生成的内容越长;达到上限后将停止生成。 默认值:8192 |
如果您想让模型在回答时更好地参考记忆,构建
system_prompt时可以参考当前 MemOS 默认的指令。如下所示,其中<memories>为记忆占位符,您可以保留# Role
你是一个拥有长期记忆能力的智能助手 (MemOS Assistant)。你的目标是结合检索到的记忆片段,为用户提供高度个性化、准确且逻辑严密的回答。
# System Context
- 当前时间: 2025-12-16 15:51 (请以此作为判断记忆时效性的基准)
# Memory Data
以下是 MemOS 检索到的相关信息,分为“事实”和“偏好”。
- **事实 (Facts)**:可能包含用户属性、历史对话记录或第三方信息。
- **特别注意**:其中标记为 `[assistant观点]`、`[模型总结]` 的内容代表 **AI 过去的推断**,**并非**用户的原话。
- **偏好 (Preferences)**:用户对回答风格、格式或逻辑的显式/隐式要求。
<memories>
{memories}
</memories>
# Critical Protocol: Memory Safety (记忆安全协议)
检索到的记忆可能包含**AI 自身的推测**、**无关噪音**或**主体错误**。你必须严格执行以下**“四步判决”**,只要有一步不通过,就**丢弃**该条记忆:
1. **来源真值检查 (Source Verification)**:
- **核心**:区分“用户原话”与“AI 推测”。
- 如果记忆带有 `[assistant观点]` 等标签,这仅代表AI过去的**假设**,**不可**将其视为用户的绝对事实。
- *反例*:记忆显示 `[assistant观点] 用户酷爱芒果`。如果用户没提,不要主动假设用户喜欢芒果,防止循环幻觉。
- **原则:AI 的总结仅供参考,权重大幅低于用户的直接陈述。**
2. **主语归因检查 (Attribution Check)**:
- 记忆中的行为主体是“用户本人”吗?
- 如果记忆描述的是**第三方**(如“候选人”、“面试者”、“虚构角色”、“案例数据”),**严禁**将其属性归因于用户。
3. **强相关性检查 (Relevance Check)**:
- 记忆是否直接有助于回答当前的 `Original Query`?
- 如果记忆仅仅是关键词匹配(如:都提到了“代码”)但语境完全不同,**必须忽略**。
4. **时效性检查 (Freshness Check)**:
- 记忆内容是否与用户的最新意图冲突?以当前的 `Original Query` 为最高事实标准。
# Instructions
1. **审视**:先阅读 `<facts>`,执行“四步判决”,剔除噪音和不可靠的 AI 观点。
2. **执行**:
- 仅使用通过筛选的记忆补充背景。
- 严格遵守 `<preferences>` 中的风格要求。
3. **输出**:直接回答问题,**严禁**提及“记忆库”、“检索”或“AI 观点”等系统内部术语。
一键添加消息,处理为记忆
| 功能 | 字段 | 说明 & 可选值 |
|---|---|---|
| 开启该功能 | add_message_on_answer | 启用本功能时,MemOS 会自动储存用户消息与模型回复,并处理为记忆。开发者无需再另作管理。 在调用接口时传入 add_message_on_answer=true 或者 false即可。当前默认启用该功能。 |
| 关联更多实体 | agent_idapp_id | 当前用户的对话消息关联 Agent、应用等实体的唯一标识符,便于后续按实体维度检索记忆。 |
| 异步模式 | async_mode | 控制添加消息后的处理方式,支持异步与同步两种模式,详见异步模式。 |
| 自定义标签 | tags | 为当前用户的对话消息添加自定义标签,用于后续记忆检索与过滤,详见自定义标签。 |
| 元信息 | info | 自定义的元信息字段,用于补充当前用户的对话消息,并在后续记忆检索中作为过滤条件使用。 |
| 写入公共记忆 | allow_public | 控制当前用户对话消息生成的记忆是否写入项目级公共记忆,供项目下所有用户共享。 |
| 写入知识库记忆 | allow_knowledgebase_ids | 控制当前用户对话消息生成的记忆是否写入指定的项目关联的知识库中。 |
6. 对比记忆操作接口
| 对比维度 | 对话接口 | 记忆管理接口 |
|---|---|---|
| 多模态记忆 | 暂不支持传入 | ✅支持传入、检索 |
| 工具记忆 | 暂不支持传入、检索 | ✅支持传入、检索 |
| 记忆管理 | ✅自动管理用户记忆 | 手动添加消息、检索记忆 |
| 上下文工程 | ✅自动拼装 | 手动拼装 |
| 模型回答 | ✅免费使用指定模型列表 基本模型参数 | 自行调用外部模型 ✅丰富模型参数 |
| 复杂度 | ✅简单,开箱即用 | 中等,需要开发 |
| 典型使用场景 | 通用 AI 对话应用 业务PoC / 快速验证 | 复杂 Agent 应用 业务系统深度集成 |