Reranker Model
Usage Examples
Rerank memory relevance based on the self-developed memos-reranker small model.
MemOS provides a memory reranking API based on the memos-reranker model series (including 0.6B lightweight and 4B enhanced versions, base model uses qwen-reranker post-training). Developers can directly pass a user query and a list of candidate memories to complete memory relevance reranking in one call.
Request/response fields and OpenAPI: Rerank Memory.
Auth, base URL, and calling conventions match MemOS Cloud Quick Start.
Auth, base URL, and calling conventions match MemOS Cloud Quick Start.
When to use memory reranking
The reranking API fits when you need:
- Memory recall optimization: After retrieving a large number of candidate memories, accurately filter out the memories most relevant to the current query through reranking to improve the quality of context injection.
- Low latency at high QPS: Based on a 0.6B small model, suitable for latency-sensitive and frequently invoked business scenarios.
- Flexible sorting control: Supports custom candidate document lists, can be used with any retrieval system, and does not rely on the MemOS memory store.
How it works
The memory reranking API and interaction with the model are shown in the figure below:
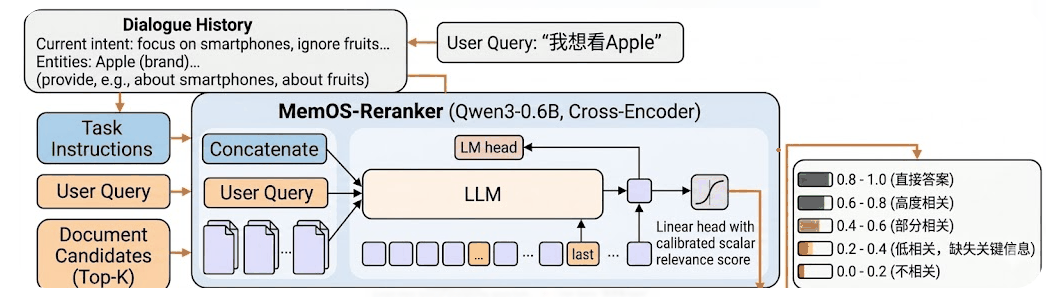
The end-to-end flow of the reranking model is as follows:
- Query Input
Developers pass in the user query (query) and the candidate memory document list (documents). - Encoding & Representation
After model encoding, relevance scores are output. - Relevance Scoring
The relevance scores are mainly divided into 5 stages as shown in the figure. Developers can set thresholds according to actual scenarios.
Get started
import os
import requests
import json
# Replace with your MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
# Available models: memos-reranker-0.6b (lightweight) or memos-reranker-4b (enhanced)
"model": "memos-reranker-0.6b",
"query": "Any liquor recommendations for me?",
"documents": [
"User prefers Jiangxiang-flavored baijiu, like Moutai.",
"I don't drink alcohol."
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/rerank"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
import os
import requests
import json
# Replace with your MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
# Available models: memos-reranker-0.6b (lightweight) or memos-reranker-4b (enhanced)
"model": "memos-reranker-0.6b",
"query": "What are the user's hobbies?",
"documents": [
"User likes playing badminton.",
"User is a backend developer in Hangzhou.",
"User prefers concise replies.",
"User prefers Jiangxiang-flavored baijiu.",
"User is going on a business trip to Beijing next Wednesday."
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/rerank"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
Limits
- Maximum length of a single document: 32k tokens.
- Maximum length of
query: 2k tokens. - Synchronous only today: the API returns all results at once after the reranking is completed.
Compared to Embedding Retrieval
| Dimension | Reranking API | Embedding Retrieval |
|---|---|---|
| Core behavior | Precision ranking of candidate docs, outputting relevance scores | Semantic similarity recall, fast coarse filtering |
| Storage | ❌ Does not write to the MemOS memory store | ❌ Does not write to the MemOS memory store |
| Model | 0.6B/4B reranking models | Embedding model |
| Precision | ✅ High (cross-encoding, query-doc interaction) | General (dual-tower encoding, independent representation) |
| Speed | Slower (requires pair-by-pair computation) | ✅ Fast (vector approximate retrieval) |
| Async | Not supported | Not supported |
| Typical use | Post-retrieval precision ranking / Memory quality assessment | Fast recall from massive memory store |