Usage Examples
Extract fact and preference memories from dialogue using the in-house memos-extractor-0.6b model.
MemOS exposes a memory extraction API powered by the in-house memos-extractor-0.6b model. Pass conversation turns in and get fact and preference memories in one call.
Request/response fields and OpenAPI: Extract Memory.
Auth, base URL, and calling conventions match MemOS Cloud Quick Start.
Auth, base URL, and calling conventions match MemOS Cloud Quick Start.
When to use memory extraction
The extraction API fits when you need:
- Lightweight extraction: Structured memories from dialogue without running the full add/message pipeline.
- Low latency at high QPS: A 0.6B in-house model tuned for fast, frequent calls.
- Flexible control: Request fact memories, preferences, or both via
extraction_types.
How it works
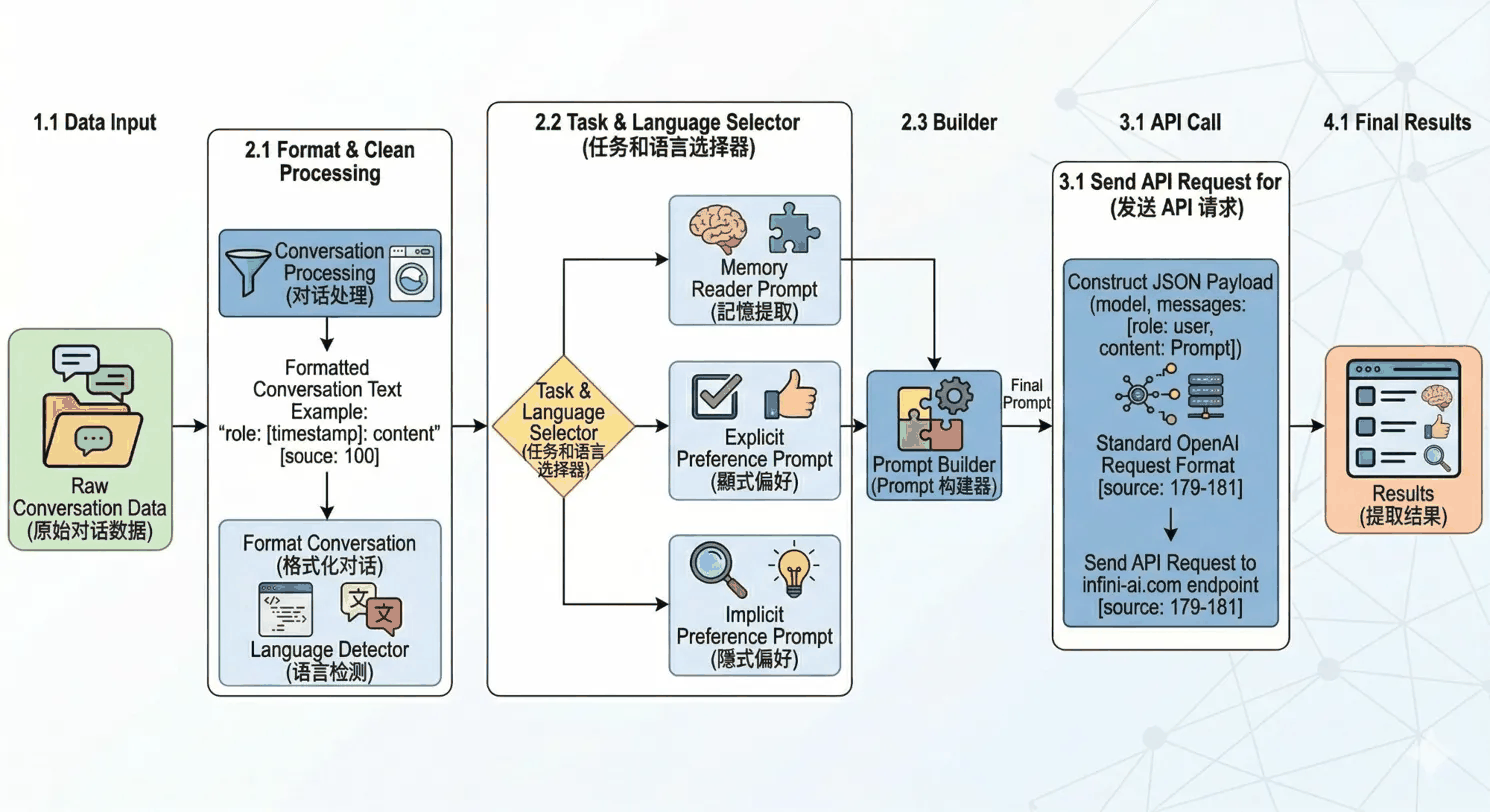
The end-to-end flow is:
- Data input
You send raw dialogue asmessageswithroleandcontenton each item. - Format & clean
Content is normalized to a standard shape and the dialogue language is detected. - Task & language selection
Usingextraction_typesand the detected language, the pipeline selects a branch:- Memory Reader: fact memories
- Explicit Preference: stated preferences
- Implicit Preference: inferred preferences
- Prompt build
The prompt template for the chosen branch is assembled into the final inference request. - API call
The request is sent to memos-extractor-0.6b in the agreed format. - Final results
The model returns structured fact and/or preference lists, depending on what you asked to extract.
Get started
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [
{"role": "system", "content": "Extract key memories from the dialogue."},
{"role": "user", "content": "I'm Alex, 28, backend dev in Hangzhou, I play badminton."},
{"role": "assistant", "content": "Hi Alex!"},
{"role": "user", "content": "Keep replies short, not too wordy."},
]
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [{"role": "user", "content": "Flying to Beijing next Wed, staying at Ji Hotel Chaoyang."}],
"extraction_types": ["memory"],
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [
{"role": "user", "content": "Use Markdown for docs, code blocks should have syntax highlighting."},
{"role": "assistant", "content": "Got it."},
{"role": "user", "content": "Also go easy on emoji."},
],
"extraction_types": ["preference"],
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
Sample responses
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"memory_detail_list": [
{
"memory_key": "User profile and job",
"memory_value": "User Alex, 28, backend developer in Hangzhou, plays badminton.",
"memory_type": "UserMemory",
"tags": ["person", "job", "location", "hobby"]
}
],
"preference_detail_list": [
{
"preference": "Wants assistant replies to stay concise and not overly verbose.",
"reasoning": "User explicitly asked to keep responses short and not too wordy.",
"preference_type": "explicit_preference"
}
]
}
}
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"memory_detail_list": [
{
"memory_key": "Travel and stay",
"memory_value": "User flies to Beijing next Wednesday on business and plans to stay at Ji Hotel in Chaoyang.",
"memory_type": "LongTermMemory",
"tags": ["travel", "trip", "hotel"]
}
]
}
}
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"preference_detail_list": [
{
"preference": "Prefers Markdown documents with syntax-highlighted code blocks.",
"reasoning": "User clearly asked for Markdown and highlighted code blocks.",
"preference_type": "explicit_preference"
},
{
"preference": "Use fewer emoji.",
"reasoning": "User directly asked to avoid too many emoji.",
"preference_type": "explicit_preference"
}
]
}
}
Limits
- Request size: up to 8,000 tokens for input.
- Synchronous only today: the API returns when extraction finishes.
- Text-only dialogue: each
messagesitem only supportsroleandcontent. No multimodal input or multimodal memory extraction through this API.
Compared to add/message
| Dimension | Extract Memory | add/message |
|---|---|---|
| Core behavior | Extract memories from dialogue; returns results only | Writes the dialogue and extracts/stores memories |
| Storage | ❌ Does not write to the MemOS memory store | ✅ Writes into the MemOS memory store |
| Model | In-house 0.6B extractor, low latency | MemOS built-in pipeline models |
| Async | Not supported | ✅ Supported |
| Preferences | ✅ Explicit + implicit | ✅ Supported |
| Tool / skill memories | ❌ Not supported | ✅ Supported |
| Typical use | Offline analysis / pre-processing / QA | Full conversational memory lifecycle |