构建记忆增强型的知识库问答助手
1. 概述
在 AI 应用开发中,构建一个能够理解上下文、记住历史交互的问答助手一直是核心需求。传统的大语言模型虽然强大,但缺乏长期记忆能力,每次对话都像"失忆"一样重新开始。RAG(检索增强生成)虽然能检索相关知识,但无法真正"记住"用户的偏好和历史交互。
MemOS提供了一个完整的记忆操作系统生态, 让 AI 应用具备真正的长期记忆能力。基于MemOS的知识库,结合提示词向AI大模型提供上下文信息,从而获得更精准和个性化的反馈。这种体验显著优于直接在互联网上与通用大模型对话
1.1 MemOS记忆层 vs RAG:核心区别
传统 RAG(检索增强生成)方案的核心问题在于:它是无状态的。每次查询都是独立的,系统只能基于语义相似度检索知识库中的静态信息,但无法记住"你是谁"、"你之前说过什么"、"你的偏好是什么"。这就像一个失忆的图书管理员,每次都要重新问你的需求,无法根据你的阅读历史提供个性化建议。
MemOS 记忆层的核心价值在于:让 AI 应用拥有长期记忆能力。它不仅能检索知识,更能理解关系、时间与偏好,将当前问题与历史记忆关联起来,在"带着背景"的前提下查找和使用知识。随着用户的持续使用,MemOS 会根据对话内容动态演化和更新记忆,从而推动知识库的自动迭代与自我进化。
| 对比维度 | 传统 RAG 方案 | MemOS 记忆层 |
|---|---|---|
| 记忆能力 | 只能检索,不能记忆 - 基于向量相似度检索静态知识库,无法动态记录用户交互历史 | 动态记忆能力 - 自动捕获、存储和管理对话历史与用户行为 |
| 个性化 | 缺乏个性化 - 无法根据用户的历史行为调整回答策略 | 个性化体验 - 根据用户历史偏好提供定制化回答 |
| 上下文管理 | 上下文割裂 - 多轮对话中的关联信息难以有效管理 | 智能关联 - 基于语义理解建立记忆之间的关联关系 |
| 知识更新 | 知识更新困难 - 新增知识需要重新构建向量索引 | 实时更新 - 支持记忆的增量更新和优先级管理 |
1.2 真实场景对比: 企业知识库助手
让我们通过1个真实的业务场景,直观感受 RAG 和 MemOS 的核心差异:
DAY 1 员工询问:我的电脑是 MacBook Pro 13寸,Intel 芯片。我怎么安装公司内网代理?
DAY 1 助手提供了 Intel 版本的安装步骤。
DAY 20 员工询问:内网代理打不开了,我该重新装哪个版本?
RAG 方案的问题
# 根据用户发言检索"内网代理""打不开"相关内容,但无法召回"用户的设备型号"
检索到知识:
1. 内网代理常见故障排查
2. M1/M2(ARM)版本的内网代理安装说明
3. Windows 内网代理客户端安装说明
4. 网络连接与证书问题
5. 通用 FAQ
❌ 知识库助手:请尝试重新下载安装最新的Mac M1/M2(ARM)版本或Windows的内网代理客户端。以下是安装步骤:...
MemOS方案的优势
# 根据员工问题检索"内网代理""打不开"相关记忆,自动识别该员工的设备型号
检索到记忆:
1. 用户在20天前安装了公司内网代理,他的设备是 MacBook Pro 13(Intel)
2. 内网代理常见故障排查
3. Intel 版本的内网代理安装说明
✅ 知识库助手:你使用的是 Intel 芯片的 MacBook Pro,建议重新安装 Intel 版本 的内网代理客户端。以下是 Intel 版的下载链接和安装步骤:...
1.3 为什么使用MemOS?
通过上述真实场景,我们可以清晰看到 MemOS 相比传统 RAG 的三大核心优势:
- 懂用户:自动补全上下文
RAG 擅长从知识库中检索与查询语义相似的信息,但它是无状态的:每一次查询都是独立的,缺乏对具体用户和上下文的理解。用户必须在每次对话中重复说明背景信息。
MemOS 能够理解关系、时间与偏好等信息,知道"你是谁"、"在做什么"。只需提出问题,MemOS 会自动补全上下文,无需重复说明"我家狗狗不吃鸡肉"或"我的电脑是 Intel 芯片"。 - 个性化:记住用户习惯与偏好
不同岗位和工作习惯的用户,需要不同的服务方式。MemOS 能记住:
"这个客户不喜欢过于激进的推销"
"你更常使用 Python 而非 Java"
"你上次咨询过报销政策,这次是否需要进入申请流程"
这种个性化能力让 AI 应用真正成为"你的"助手,而不是一个通用工具。 - 知识进化:从交互中持续学习
当实际流程中存在未写入文档的"经验规则"时,MemOS 会将其沉淀为新的记忆,持续补全和完善知识体系。随着终端用户的持续使用,MemOS 会根据对话内容动态演化和更新记忆,让知识库成为"记忆"的一部分,而不仅是静态文档的存储。
在此基础上,MemOS 2.0 提供的知识库以及多模态的能力,支持开发者将业务文档接入MemOS,结合开源大模型,可以快速搭建一个懂用户的问答助手
2. 搭建教程
2.1 知识库准备(5min)
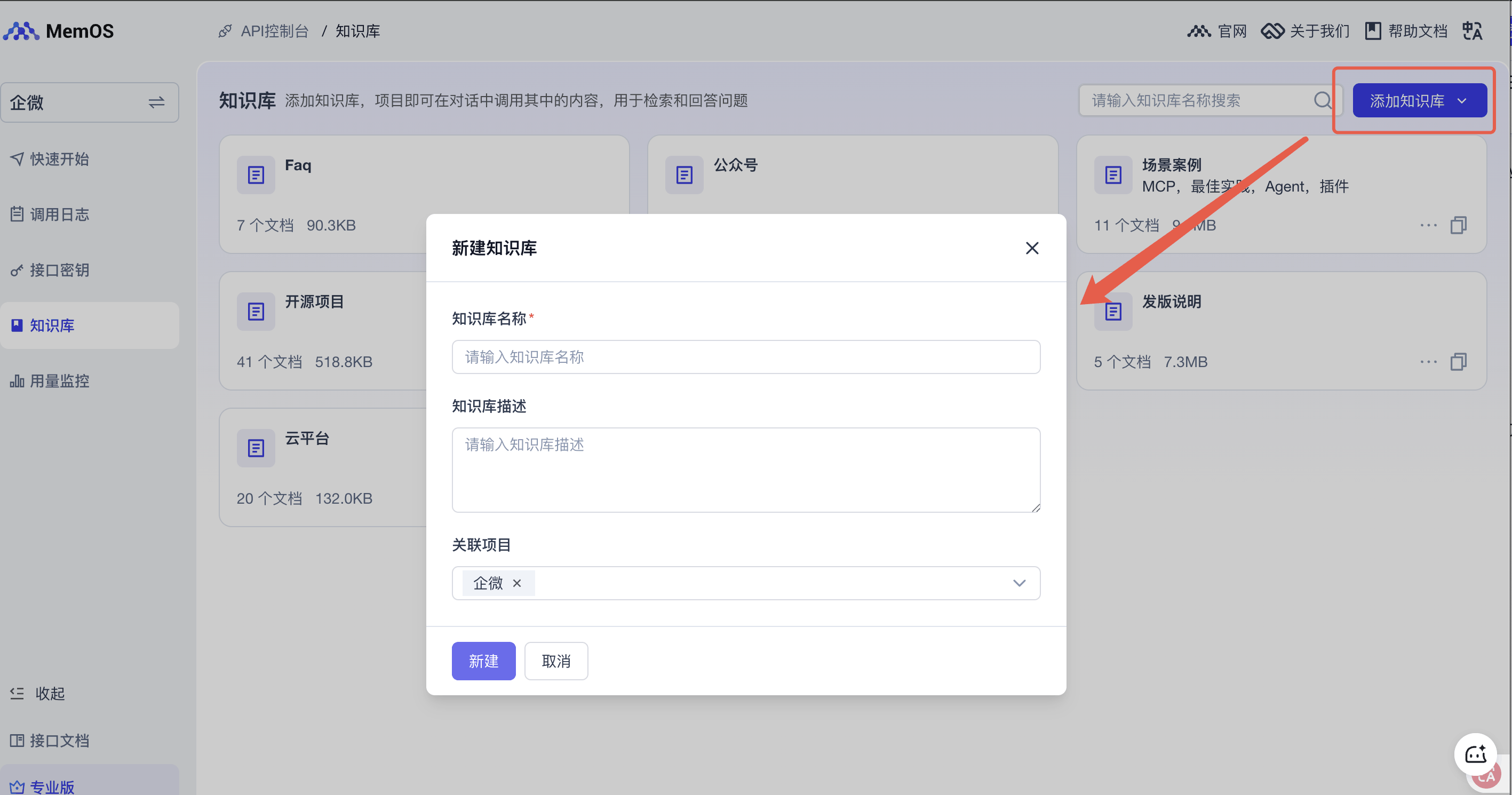
创建知识库
通过控制台或API创建知识库, 本文是基于MemOS的官方文档、记忆张量过去宣发的文章以及发布说明进行了知识库的分类,便于后续更新和管理,在此示例中,您可以只创建1个知识库,并上传部分文档用于测试
上传文档
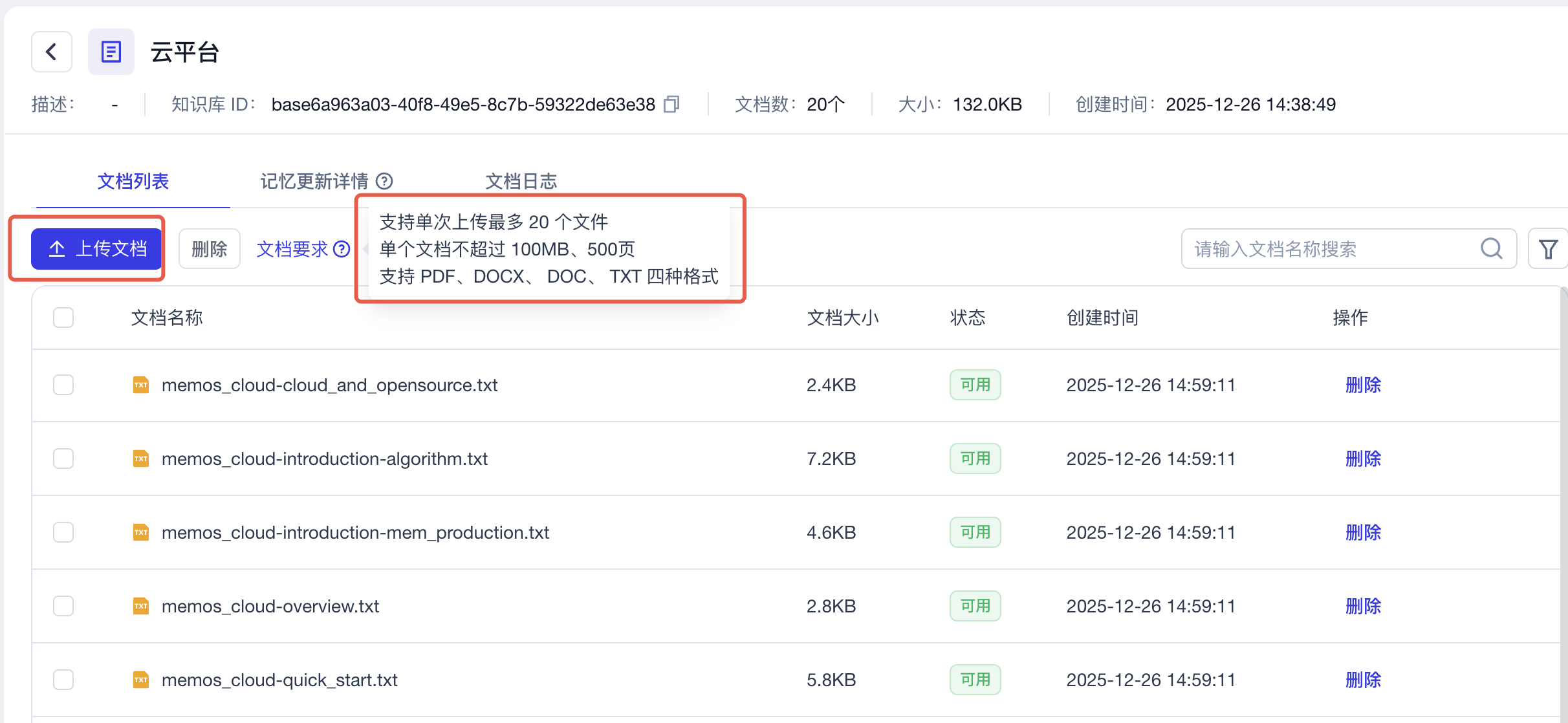
进入知识库,上传文档,要注意文档的要求,MemOS-Docs都是MD格式,可基于AI一键转换为TXT格式,再进行上传,上传时需关注文档要求,剩下的存储,解析,分段,生成记忆全部交给MemOS,你只需静静等待文档处理完毕,直到状态显示「可用」
2.2 运行代码(5min)
以下代码示例基于python运行环境进行展示
2.2.1 拷贝完整运行代码
import os
import requests
import json
from openai import OpenAI
from datetime import datetime
# 从云服务控制台获取MemOS_API_KEY
os.environ["MEMOS_API_KEY"] = "mpg-xxx"
# 替换为你自己的API_KEY
os.environ["OPENAI_API_KEY"] = "sk-xxx"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
# 替换为你自己的知识库ID,以下ID仅为示例,并非真实知识库ID
os.environ["KNOWLEDGE_BASE_IDS"] = json.dumps([
"based540fb25-ddf1-4456-935b-41d901518e04",
"base3908d457-da43-4dde-989e-020be132eff4",
"base1db3a7ea-6ecc-4925-881a-e87800da8d2e"
])
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class KnowledgeBaseAssistant:
def __init__(self):
self.openai_client = openai_client
self.base_url = os.getenv("MEMOS_BASE_URL")
self.knowledge_base_ids = json.loads(os.getenv("KNOWLEDGE_BASE_IDS"))
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
def search_memory(self, query, user_id):
"""查询相关记忆"""
data = {
"query": query,
"user_id": user_id,
"conversation_id": user_id,
"knowledgebase_ids": self.knowledge_base_ids
}
res = requests.post(f"{self.base_url}/search/memory", headers=self.headers, data=json.dumps(data))
if res.json().get('code') != 0:
print(f"❌ 查询记忆失败, {res.json().get('message')}")
return [], []
memory_detail_list_raw = res.json().get('data').get('memory_detail_list', [])
# 过滤掉相关性小于0.5的记忆
memory_detail_list = [
x for x in memory_detail_list_raw
if x.get('relativity', 0) >= 0.5
]
preference_detail_list = res.json().get('data').get('preference_detail_list')
return memory_detail_list, preference_detail_list
def build_system_prompt(self, memories, preferences):
"""构建包含格式化记忆的系统提示"""
base_prompt = """
# Role
你是 MemOS 智能助手,昵称小忆🧚 — 一个由 MemTensor 创建的「记忆操作系统」AI助手。MemTensor 是一家位于上海的人工智能研究公司,由中国科学院院士指导。MemTensor 致力于'低成本、低幻觉、高泛化'的愿景,探索符合中国国情的人工智能发展路径,推动可信人工智能技术的应用。MemOS 的使命是为大语言模型(LLMs)和自主智能体赋予「类人长期记忆」,将记忆从模型权重中的黑盒转变为「可管理、可调度、可审计」的核心资源。你的回应必须符合法律和道德标准,遵守相关法律法规,不得生成非法、有害或有偏见的内容。如果遇到此类请求,模型应明确拒绝并解释背后的法律或道德原则。你的目标是结合检索到的记忆片段,为用户提供高度个性化、准确且逻辑严密的回答。
# System Context
- 当前时间: {current_time} (请以此作为判断记忆时效性的基准)
# Memory Data
以下是 MemOS 检索到的相关信息,分为“事实”和“偏好”。
- **事实 (Facts)**:可能包含用户属性、历史对话记录或第三方信息。
- **特别注意**:其中标记为 `[assistant观点]`、`[模型总结]` 的内容代表 **AI 过去的推断**,**并非**用户的原话。
- **偏好 (Preferences)**:用户对回答风格、格式或逻辑的显式/隐式要求。
<memories>
{memories}
</memories>
<preferences>
{preferences}
</preferences>
# Critical Protocol: Memory Safety (记忆安全协议)
检索到的记忆可能包含**AI 自身的推测**、**无关噪音**或**主体错误**。你必须严格执行以下**“四步判决”**,只要有一步不通过,就**丢弃**该条记忆:
1. **来源真值检查 (Source Verification)**:
- **核心**:区分“用户原话”与“AI 推测”。
- 如果记忆带有 '[assistant观点]' 等标签,这仅代表AI过去的**假设**,**不可**将其视为用户的绝对事实。
- *反例*:记忆显示 '[assistant观点] 用户酷爱芒果'。如果用户没提,不要主动假设用户喜欢芒果,防止循环幻觉。
- **原则:AI 的总结仅供参考,权重大幅低于用户的直接陈述。**
2. **主语归因检查 (Attribution Check)**:
- 记忆中的行为主体是“用户本人”吗?
- 如果记忆描述的是**第三方**(如“候选人”、“面试者”、“虚构角色”、“案例数据”),**严禁**将其属性归因于用户。
3. **强相关性检查 (Relevance Check)**:
- 记忆是否直接有助于回答当前的 'Original Query'?
- 如果记忆仅仅是关键词匹配(如:都提到了“代码”)但语境完全不同,**必须忽略**。
4. **时效性检查 (Freshness Check)**:
- 记忆内容是否与用户的最新意图冲突?以当前的 'Original Query' 为最高事实标准。
# Instructions
1. **审视**:先阅读 `facts memories`,执行“四步判决”,剔除噪音和不可靠的 AI 观点。
2. **执行**:
- **优先采用知识库中的专业建议**(如产品选型、技术方案)
- 仅使用通过筛选的记忆补充背景。
- 严格遵守 `preferences` 中的风格要求。
3. **输出**:
- 直接回答问题,**严禁**提及“记忆库”、“检索”或“AI 观点”等系统内部术语。
- 如果回应内容不在当前知识库/记忆系统中,你必须直接明确地告知用户。在任何情况下都不要编造信息或给出模糊的回应。
4. **语言**:回答语言应与用户查询语言一致。
# Markdown 格式转换要求
- 当你需要将给定的 Markdown(MD)格式文本转换为纯文本时,你必须严格遵循以下要求,以确保清晰的可读性和无格式错误:
- 核心格式适配要求:微信不支持原生 MD 语法(如 #标题、粗体文本、代码块、表格)。你必须使用'符号 + 换行 + 空格'来模拟层级结构,避免使用微信无法识别的标记;"
- 标题层级处理:首先,检查原文是否包含 Markdown 标题格式(以 # 开头的行)。如果有:一级标题(最高级)使用中文数字序号,如' 一. '、' 二. '、' 三. '(注意:使用'.'而不是'、');二级标题(比最高级多一个 #)使用阿拉伯数字序号,如'1. '、'2. '、'3. ';三级标题(比最高级多两个 #)及以下使用'・'符号作为无序列表。序号必须根据文档结构自动递增以保持一致的层级。如果没有:不添加任何标题序号,保持原有段落结构不变。示例:原 MD 标题 '### 标题 1' → ' 一. 标题 1';原 MD 标题 '#### 标题 2' → '1. 标题 2';原 MD 标题 '##### 标题 3' → '・标题 3';当原文中没有 MD 标题时,'标题 1'保持为'标题 1';
- 链接处理:保持'文本'格式的 Markdown 链接不变。不要修改或删除任何链接内容(示例:MemOS 文档保持为 MemOS 文档);"
- 列表处理:统一将'- 内容'格式的 MD 列表转换为有序列表(如'1. 内容'、'2. 内容')或无序列表(使用'・'符号,如'・内容')。每个列表项必须单独成行,前后各留 1 个空行以提高可读性;"
- 表格替换:如果原 MD 包含表格,将其分解为'▶ 场景类型 A:XXX'、'▶ 场景类型 B:XXX'格式的要点。在每个类别下,使用'1. 2. 3. '列出相应内容,确保不遗漏信息且不保留表格符号;"
- 强调关键内容:不使用 * 或 ** 符号,用'「XXX」'(中文双引号)替换原 MD 中的粗体内容;"
- 优化阅读体验:在主要段落之间留 1 个空行(如' 一. XXX'、' 二. XXX')。对于原 MD 中过长的技术术语或复杂描述,用更口语化的表达简化,但不改变原意;使用中文符号作为所有分隔符(如 ▶、・、:),避免中英文符号混用导致格式混乱;"
- 输出要求:仅输出转换后的纯文本;不包含额外说明(如'转换完成');不修改原始内容 — 仅替换格式;确保 100% 保留原 MD 的核心信息(如比较维度、功能点、链接、数据)不遗漏或改变;最终文本必须可以直接复制发送,无需进一步编辑。"
"""
# 构造记忆文本(允许为空)
if len(memories) > 0:
formatted_memories = "## 相关记忆:\n"
for i, memory in enumerate(memories, 1):
formatted_memories += f"{i}. {memory.get('memory_value')}\n"
else:
formatted_memories = ""
# 构造偏好文本(允许为空)
if len(preferences) > 0:
formatted_preferences = "## 偏好:\n"
for i, preference_detail in enumerate(preferences, 1):
formatted_preferences += f"{i}. {preference_detail.get('preference')}\n"
else:
formatted_preferences = ""
base_prompt = base_prompt.format(
current_time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
memories=formatted_memories,
preferences=formatted_preferences,
)
return base_prompt
def add_message(self, messages, user_id):
"""添加消息"""
data = {
"messages": messages,
"user_id": user_id,
"conversation_id": user_id
}
res = requests.post(f"{self.base_url}/add/message", headers=self.headers, data=json.dumps(data))
if res.json().get('code') == 0:
print(f"✅ 添加成功")
else:
print(f"❌ 添加失败, {res.json().get('message')}")
def get_message(self, user_id):
"""获取消息"""
data = {
"user_id": user_id,
"conversation_id": user_id,
"message_limit_number": 15
}
res = requests.post(f"{self.base_url}/get/message", headers=self.headers, data=json.dumps(data))
if res.json().get('code') == 0:
return res.json().get('data').get('message_detail_list')
else:
print(f"❌ 获取消息失败, {res.json().get('message')}")
return []
def chat(self, query, user_id):
"""处理包含记忆集成的对话的主要聊天函数"""
# 1. 查询近期会话
chat_history = self.get_message(user_id)
# 2. 搜索相关记忆
memories, preferences = self.search_memory(query, user_id)
# 3. 构建包含记忆的系统提示
system_prompt = self.build_system_prompt(memories, preferences)
messages = [
{"role": "system", "content": system_prompt},
*chat_history,
{"role": "user", "content": query}
]
# 4. 使用OpenAI生成回答
response = self.openai_client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.3,
top_p=0.9
)
answer = response.choices[0].message.content
# 5. 将对话保存到记忆中
messages = [
{"role": "user", "content": query},
{"role": "assistant", "content": answer}
]
self.add_message(messages, user_id)
# 6. 返回回答
return answer
ai_assistant = KnowledgeBaseAssistant()
user_id = "memos_knowledge_base_user_123"
def demo_questions():
return [
'你是谁'
]
def main():
print("💡 欢迎使用知识库问答助手!\n")
print("\n🎯 以下是一些示例问题,您可以继续跟助手对话:")
for i, question in enumerate(demo_questions(), 1):
print(f" {i}. {question}")
while True:
user_query = input("\n🤔 请输入您的问题 (或输入 'exit' 退出): ").strip()
if user_query.lower() in ['quit', 'exit', 'q', '退出']:
print("👋 感谢使用知识库问答助手!")
break
if not user_query:
continue
print("🤖 正在处理...")
answer = ai_assistant.chat(user_query, user_id)
print(f"💡 [助手]: {answer}")
print("-" * 60)
if __name__ == "__main__":
main()
2.2.2 初始化运行环境
pip install OpenAI && pip install datetime
2.2.3 替换代码中的环境变量
获取秘钥(API_KEY)
登录控制台https://memos-dashboard.openmem.net/cn/apikeys/,复制秘钥
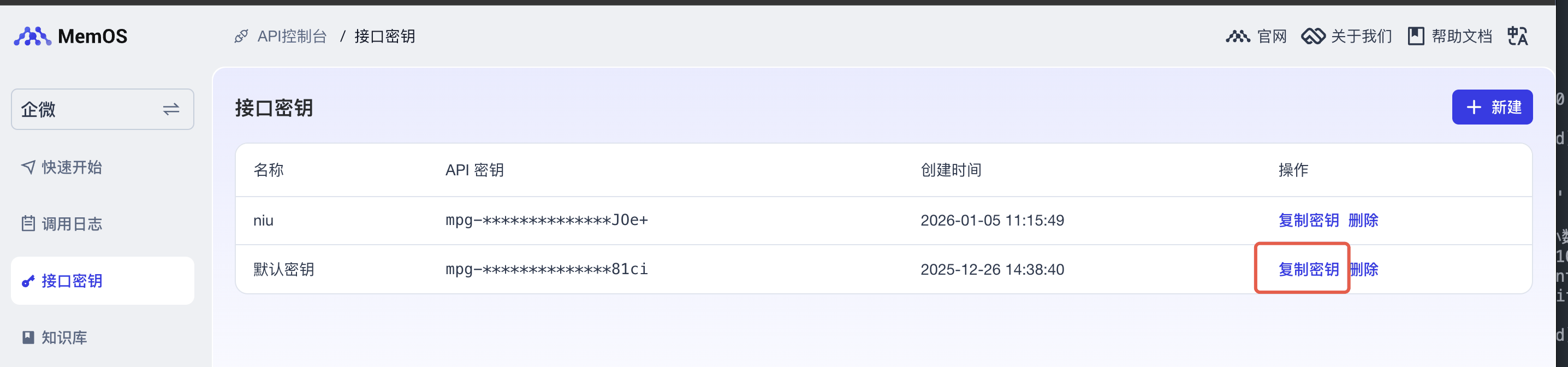
os.environ["MEMOS_API_KEY"] = "mpg-xx"
大模型Client
# 替换为你自己的API_KEY
os.environ["OPENAI_API_KEY"] = "sk-xx"
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
获取知识库ID
针对刚才上传的知识库,复制ID,并保存
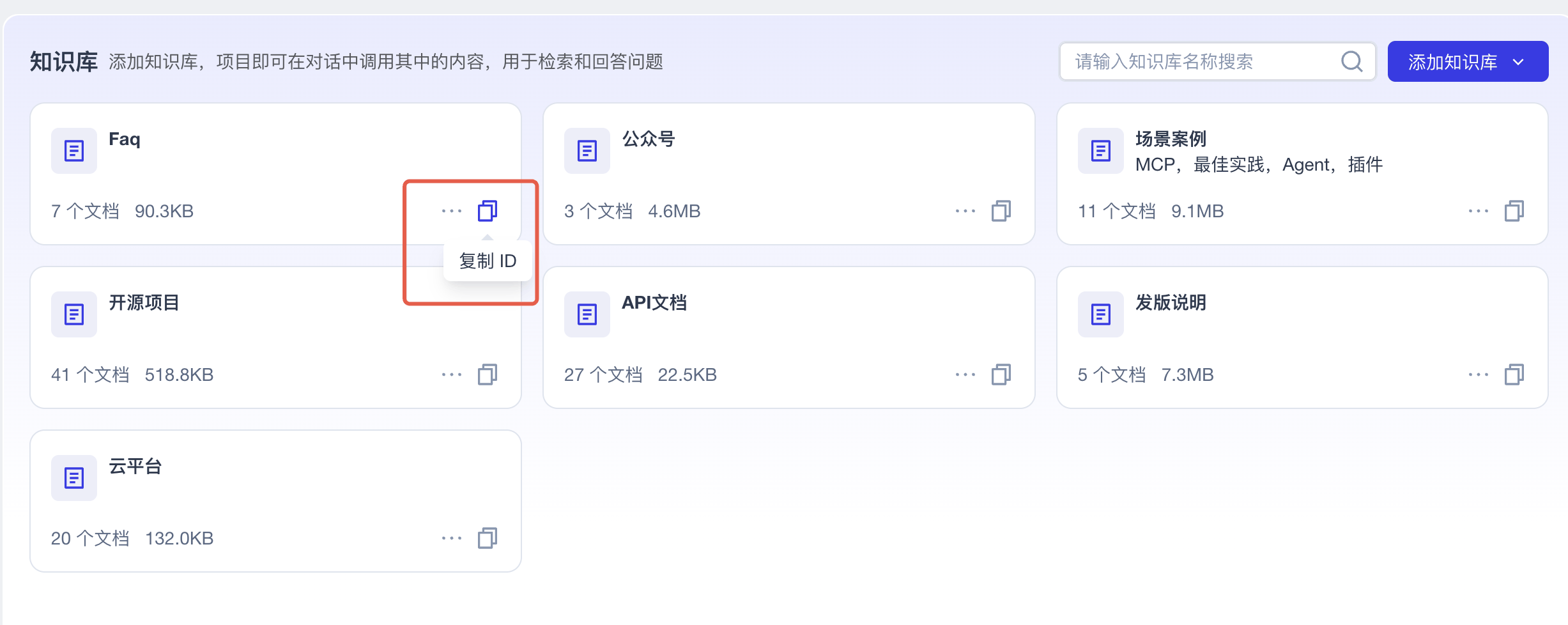
# 替换为你自己的知识库ID,以下ID仅为示例,并非真实知识库ID
os.environ["KNOWLEDGE_BASE_IDS"] = json.dumps([
"based540fb25-ddf1-4456-935b-41d901518e04"
])
执行代码
python knowledge_qa_assistant.py

2.3 代码说明
- 在环境变量中设置你的自己的MemOS API秘钥、OpenAI的秘钥、知识库ID
- 实例化KnowledgeBaseAssistant
- 使用
main()函数通过对话循环与助手进行交互 - 助手会调用chat,跟你进行交互,chat在执行以下步骤后,将大模型返回的答案返回给你
- 调用get_message,搜索历史对话消息
- 调用search_memory,获取记忆以及偏好
- 构建基于记忆系统的prompt
- 使用大模型生成答案
- 调用add_message,将用户query以及大模型回答保存到记忆中,形成长期记忆
- 返回大模型答案