重排模型
使用示例
基于自研 memos-reranker 模型,提供记忆相关性重排能力。
MemOS 提供记忆重排接口,基于 memos-reranker 系列模型(包括 0.6B 轻量版和 4B 增强版,基础模型采用 qwen-reranker 后训练),开发者可直接传入用户查询与候选记忆列表,一键完成记忆相关性重排。
何时使用记忆重排模型
记忆重排接口适用于以下场景:
- 记忆召回优化:在检索到大量候选记忆后,通过重排精准筛选出与当前查询最相关的记忆,提升上下文注入质量。
- 低延迟高频调用:基于 0.6B 小模型,适合对延迟敏感、调用频繁的业务场景。
- 灵活的排序控制:支持自定义候选文档列表,可与任意检索系统配合使用,不依赖 MemOS 记忆库。
不建议在下面场景直接调用重排接口:
- 还没有候选文档,只是想从记忆库里查找内容。此时应先调用 Search Memory。
- 希望把内容写入记忆。重排接口不会写入 MemOS 记忆库,应使用 Add Message。
- 想对超长文档全文排序。请先检索、切分或截断候选内容,再把较短候选片段传给
documents。
工作原理
记忆重排的 API 以及与模型的交互如下图所示:
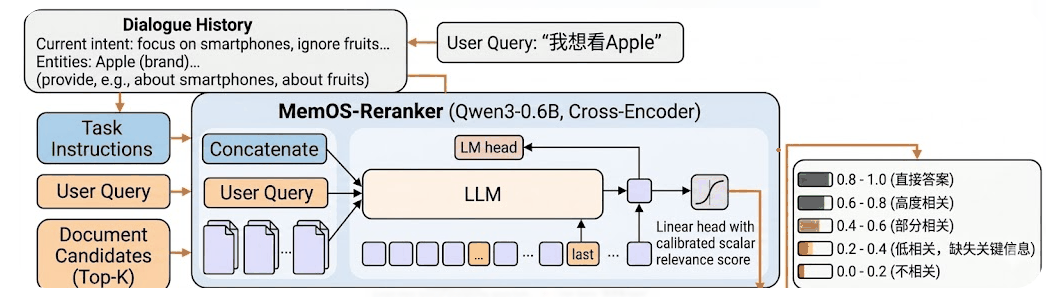
重排模型的完整调用流程如下:
- 查询输入
开发者传入用户查询(query)和候选记忆文档列表(documents)。 - 编码与表征
经过模型编码输出相关性分数。 - 相关性打分
相关性分数主要分为 5 个阶段如图所示,开发者可以根据实际场景进行阈值的设定。
快速上手
import os
import requests
import json
# 替换成你的 MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
# 可选模型:memos-reranker-0.6b(轻量版)或 memos-reranker-4b(增强版)
"model": "memos-reranker-0.6b",
"query": "有什么酒可以推荐给我呢",
"documents": [
"用户比较喜欢酱香型的,比方说茅台",
"我不喝酒"
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/rerank"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
import os
import requests
import json
# 替换成你的 MemOS API Key
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
# 可选模型:memos-reranker-0.6b(轻量版)或 memos-reranker-4b(增强版)
"model": "memos-reranker-0.6b",
"query": "用户有什么兴趣爱好",
"top_n": 3,
"documents": [
"用户喜欢打羽毛球",
"用户在杭州做后端开发",
"用户偏好简洁的回复风格",
"用户比较喜欢酱香型白酒",
"用户下周三要去北京出差"
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}"
}
url = f"{os.environ['MEMOS_BASE_URL']}/rerank"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
使用限制
query为必填,建议传入清晰、短句式的当前问题。documents为必填,必须是非空字符串数组;数组中所有候选文档的总 token 数上限为 8k。top_n可选,用于返回前 N 条最相关结果;不传时默认返回全部结果。model可选,支持memos-reranker-0.6b和memos-reranker-4b。- 当前仅支持同步模式,接口将在重排完成后一次性返回结果。
常见错误与排查
| 错误码 | 常见原因 | 处理方式 |
|---|---|---|
40000 | 请求体结构错误,或字段类型不符合要求 | 检查 query 是否为字符串,documents 是否为字符串数组 |
40002 / 40003 | 必填字段为空,或 documents 为空 | 补充 query 和非空 documents,不要传空数组 |
40309 | 单位时间输入 token 超限 | 减少候选文档数量和长度,降低调用并发,分批重试 |
50000 | 系统内部异常 | 稍后重试;如果持续出现,请联系支持 |
对比 Embedding 检索
| 对比维度 | 记忆重排接口 | Embedding 向量检索 |
|---|---|---|
| 核心能力 | 对候选文档精排,输出相关性分数 | 语义相似度召回,快速粗筛 |
| 记忆存储 | ❌ 不写入 MemOS 记忆库 | ❌ 不写入 MemOS 记忆库 |
| 推理模型 | 0.6B/4B 重排模型 | Embedding 模型 |
| 精度 | ✅ 高(交叉编码,query-doc 交互) | 一般(双塔编码,独立表征) |
| 速度 | 较慢(需逐对计算) | ✅ 快(向量近似检索) |
| 异步模式 | 暂不支持 | 暂不支持 |
| 典型使用场景 | 检索后精排 / 记忆质量评估 | 海量记忆库快速召回 |